--- 1618,1624 ----
|
! Boolean (BL)
|
|---|
|
***************
*** 1927,1933 ****
information was missing afterwards. We will factor this "update"
component out into update semantics
below. Here we only deal with the representation of incomplete
! information.
After having defined the Boolean, the type that underlies all
information, we now define a data type called "No Information" as
--- 1782,1789 ----
information was missing afterwards. We will factor this "update"
component out into update semantics
below. Here we only deal with the representation of incomplete
! information. This means, NULL values do no longer automatically carry
! the notion of "deleting" or "overwriting" with them.
After having defined the Boolean, the type that underlies all
information, we now define a data type called "No Information" as
***************
*** 1945,1951 ****
A No Information value can occur in place of any other value to
express that specific information is missing and how or why it is
missing. This is like a NULL in SQL but with the ability to specify a
! certain flavor of missing information.
|
| component name |
--- 1801,1809 ----
A No Information value can occur in place of any other value to
express that specific information is missing and how or why it is
missing. This is like a NULL in SQL but with the ability to specify a
! certain flavor of missing information. The No Information type extends
! the value domain of any other data type unless explicitly forbidden by
! domain constraints.
| component name |
***************
*** 1968,2010 ****
the information is missing. For the time being we keep the list of
possible flavors of null subject to open discussions. Reported numbers
of different flavors of null values range between 1 (SQL) and 70
! (reported by Angelo Rossi-Mori).
!
! If No-Information flavors are to be used in a standard way, we will
! have to define a canonical systematization of flavors of null.
!
! For example, Stan Huff's CE proposal contains the following null
! values:
!
!
!
! | U | unknown
! | no information at all. I.e. nothing more is known about the
! circumstances of missing information.
! | | UASK | asked but unknown
! | the person asked could not supply the information
! (why?)
! | | NAV | not available
! | the person asked does have the information somewhere
! but not available right now (e.g. oh, I wrote down what
! the doctor said last time, but I didn't bring this piece
! of paper with me).
! | | NA | not applicable
! | e.g. an answer to "gestational age" for a patient
! who is not pregnant.
! | | NASK | not asked
! | the person who should collect that information forgot to
! ask.
! |
!
! The above example list provides no assurance to be complete or
! sufficient and it does not attempt to systematize the many possible
! flavors of null. It serves here as an example to show what such
! flavors of null can comprise. Now that we defined a fairly general
! data type for no information, and as we factored update semantics
! into its own method, this issue of a canonical taxonomy of null values
! is less important. In most cases, all what people need is a No
! Information value without the flavor component.
For example, consider the patient's date of birth is requested and
we don't know the date of birth because the patient does not remember
--- 1826,1900 ----
the information is missing. For the time being we keep the list of
possible flavors of null subject to open discussions. Reported numbers
of different flavors of null values range between 1 (SQL) and 70
! (reported by Angelo Rossi-Mori). If No-Information flavors are to be
! used in a standard way, we have to define a canonical systematization
! of flavors of null. The following table lists a number of canonical
! null value flavors plus additional flavors of null which still need to
! be systematized.
!
!
! | NI | no information
canonical
! | This is the default null value. It simply says that there
! is no information whatsoever given in the context where the NI
! value occurs. The information may or may not be available
! elsewhere, it may or may not be applicable or known. The NI
! value can not be interpreted any further. |
! | NA | not applicable
canonical
! | The data element does not apply in a given context, e.g. an
! answer to "gestational age" for a patient who is not
! pregnant. |
! | UNK | unknown
canonical
! | The information may be applicable, but is not known in the
! given context. |
! | OTH | other
canonical
! | The information is known but can not be expressed in the
! required constraints. Most often used when a concept needs to be
! coded but the code system does not provide for the appropriate
! concept. Many code systems have an "other" entry (also called
! "not otherwise specified".) Terminologies should not themselves
! contain "other" entries [Cimino ??]. The null value of the OTH
! flavor can and should replace those "other"
! codes. Note: this flavor is
! not itself a "not otherwise specified" code
! for null flavors.
! |
! | NASK
! | not asked
! | the person who should
! collect that information forgot to ask. Needs further
! systematization. |
! | ASKU
! | asked but unknown
! | the person asked could
! not supply the information (why?) Needs further
! systematization. |
! | NAV
! | not available
! | the person asked does
! have the information somewhere but not available right now
! (e.g. oh, I wrote down what the doctor said last time, but
! I didn't bring this piece of paper with me). Such data
! elements might be updated soon. Needs further systematization.
! |
! | NP
! | not present
special
! |
! The not present value is only meaningful within a message,
! not within a system's data base. The not-present flavor must
! be replaced by the applicable default value at the receiving
! interface. If no other default value is specified, a No
! Information value with the dafalut flavor no information is
! used.
! |
!
!
! In most cases, the No Information value with the default flavor
! no information is sufficient. So, if the flavors of null are
! deemed not useful for technical committees or implementors, they can
! simply assume no flavors to exist other than the default no
! information flavor (which would translate to an SQL NULL) and the
! special flavor not present which is only applicable for
! messages and is replaced by a default value at a receiving interface.
For example, consider the patient's date of birth is requested and
we don't know the date of birth because the patient does not remember
***************
*** 2013,2039 ****
(Patient
:date-of-birth (NoInformation
! :flavor (CV :value "UASK"
! :codeSystem "SHNULLS")))
In this example instance notation we will use the symbol
#null to be equivalent with (NoInformation)
! without a flavor.
Note that No Information is formally a composite data type,
although it has but one component. We will list No Information under
the category "primitive" anyway, since it is so fundamental to our
! type system.
1.2.12 Update Semantics
Update semantics deals with the problem of what a receiver is
! supposed to do with information in the message. That information may
! be equal to prior information at the receivers data base, in which
! case no questions occur. But what if the information is different?
We can categorize the modes of updates in the following taxonomy:
--- 1903,1967 ----
(Patient
:date-of-birth (NoInformation
! :flavor (CV :value "ASKU")))
In this example instance notation we will use the symbol
#null to be equivalent with (NoInformation)
! with the implied default flavor no information.
Note that No Information is formally a composite data type,
although it has but one component. We will list No Information under
the category "primitive" anyway, since it is so fundamental to our
! type system. This is a very special data type anyway, since it will
! never be used in declaring attributes or data elements, but will
! rather extend every data type to provide for a consistent way to
! account for missing information.
!
! Note that extended Boolean logic (e.g., three-valued logic) is
! supported using the classic Boolean data type with the implied domain
! extension offered by the No Information values. The third value of
! three-valued logic would be the No Information value (of any flavor.)
! The logic operators that apply in three valued logic are defined in
! the following tables:
!
!
!
! Definition of logic operators in three-valued logic
!
!
! | NOT | |
|---|
! | true | false |
! | false | true |
! | ni | ni |
!
! |
!
! | AND | true | false | ni |
|---|
! | true | true | false | ni |
! | false | false | false | false |
! | ni | ni | false | ni |
!
! |
!
! | OR | true | false | ni |
|---|
! | true | true | true | true |
! | false | true | false | ni |
! | ni | true | ni | ni |
!
! |
!
!
1.2.12 Update Semantics
Update semantics deals with the problem of what a receiver is
! supposed to do with information (or "no information") in a
! message. That information may be equal to prior information at the
! receivers data base, in which case no questions occur. But what if the
! information is different?
We can categorize the modes of updates in the following taxonomy:
***************
*** 2116,2125 ****
should be part of the MEI meta model.
! It turns out that updating a list is the most difficult task to do,
! since positions are relevant in the list. The problem is concurrent
! updates; you never know exactly what the list looks like at the
! receiver's data base when your update message is being processed.
For example, if you think the list is (LIST A B C) and
you want to insert an element D to come before
--- 2044,2053 ----
should be part of the MEI meta model.
! It turns out that updating a list is the most difficult task
! to do, since positions are relevant in the list. The problem is
! concurrent updates; you never know exactly what the list looks like at
! the receiver's system when your update message is being processed.
For example, if you think the list is (LIST A B C) and
you want to insert an element D to come before
***************
*** 2344,2361 ****
terminals. Originally, those were control sequences separated from the
normal text by a leading ASCII character number 27 ("escape"), hence
the name "escape sequence". But escape sequences have since been used
! in many different styles. In C string literals, troff, TeX and RTF we
! see the backslash character (\) introducing escape
! sequences. Troff has a second kind of escape sequences started by a
! period at the beginning of a new line. HL7 version 2 also uses the
! backslash at the beginning and end of escape sequences. SGML uses
angle brackets to enclose escape sequences (markup tags), but in
addition there are other kinds of escape sequences in SGML opened with
the ampersand or percent sign and closed with a semicolon (entity
references).
From the many choices to encode formatted text HL7 traditionally
! used a few special escape sequences and troff-style formatting
commands. Those HL7 escape sequences have the disadvantage that they
are is not very powerful and somewhat arcane or at least outdated by
the more recent developments. HTML has become the most widely deployed
--- 2272,2291 ----
terminals. Originally, those were control sequences separated from the
normal text by a leading ASCII character number 27 ("escape"), hence
the name "escape sequence". But escape sequences have since been used
! in many different styles. In C string literals,
! TROFF,
! TEX
! and RTF we see the backslash character (\) introducing
! escape sequences. TROFF has a second kind of escape sequences started
! by a period at the beginning of a new line. HL7 version 2 also uses
! the backslash at the beginning and end of escape sequences. SGML uses
angle brackets to enclose escape sequences (markup tags), but in
addition there are other kinds of escape sequences in SGML opened with
the ampersand or percent sign and closed with a semicolon (entity
references).
From the many choices to encode formatted text HL7 traditionally
! used a few special escape sequences and TROFF-style formatting
commands. Those HL7 escape sequences have the disadvantage that they
are is not very powerful and somewhat arcane or at least outdated by
the more recent developments. HTML has become the most widely deployed
***************
*** 2394,2405 ****
attribute. There is hardly any rationale for such a decision at design
time of the standard.
! Thus, the irrationality and inflexibility of defining multiple
! data types for free text seems to outweigh the conceivable advantage
! that a special data type might accommodate the intrinsics of some
! special encoding formats in greater detail and accuracy. Thus, we
! define only one flexible data type for free text, that can support all
! the techniques for encoding appearance of free text.
2.1.4 From appearance of text to multimedial information
--- 2324,2335 ----
attribute. There is hardly any rationale for such a decision at design
time of the standard.
! Thus, the irrationality and inflexibility of defining multiple data
! types for free text seems to outweigh the conceivable advantage that a
! special data type might accommodate the intrinsics of some special
! encoding formats in greater detail and accuracy. Thus, we define only
! one flexible data type for free text, that can support all the
! techniques for encoding appearance of free text.
2.1.4 From appearance of text to multimedial information
***************
*** 2447,2464 ****
data in any free text field, and thus, that free text and multimedia
data share the same data type. This is not hard to do since one
flexible data type was already required to accommodate the different
! encodings of text formats.
2.1.5 Pulling the pieces together
In the previous exploration of the field of text, we separated out
the difference between string data elements, where the raw information
! of characters is sufficient and free text, where there is use for
formatting the text and augment or even replace the text with
! multimedia information. This means that there will be a string data
! type on the one hand, and a flexible data type that covers free text
! and multimedial data on the other.
!
2.2 Character String
--- 2377,2453 ----
data in any free text field, and thus, that free text and multimedia
data share the same data type. This is not hard to do since one
flexible data type was already required to accommodate the different
! encodings of text formats. We will call this data type "Display Data"
! and it is used for both free text and multimedia. Display Data will
! consist of a media descriptor code and the data itself. Applications
! will render the data differently depending on the media descriptor
! code.
!
! Although it is technicallz convenient to merge character-based free
! text and multimedia data into one data type, the rationale of this
! decision is semantic not technical. Both, character based free text
! and multimedia data is information sent primarily to human beings for
! theiur interpretation. This conforms to the meaning of the word "text"
! as explained by Webster's dictionary:
!
!
! Main Entry: text
! Pronunciation: 'tekst
! Function: noun
! Etymology: Middle English, from Middle French texte, from
! Medieval Latin textus, from Latin, texture, context, from
! texere to weave -- more at TECHNICAL
! Date: 14th century
! 1 a (1) : the original words and form of a written or
! printed work (2) : an edited or emended copy of an original
! work b : a work containing such text
2 a
! : the main body of printed or written matter on a page b
! : the principal part of a book exclusive of front and back
! matter c : the printed score of a musical
! composition
3 a (1) : a verse or passage of Scripture
! chosen especially for the subject of a sermon or for authoritative
! support (as for a doctrine) (2) : a passage from an
! authoritative source providing an introduction or basis (as for a
! speech) b : a source of information or
! authority
4 : THEME,
! TOPIC
5 a : the words of
! something (as a poem) set to music b : matter chiefly in
! the form of words that is treated as data for processing by
! computerized equipment <a text-editing
! typewriter>
6 : a type suitable for printing
! running text
7 : TEXTBOOK
!
8 a : something
! written or spoken considered as an object to be examined, explicated,
! or deconstructed b : something likened to a text <the
! surfaces of daily life are texts to be explicated --
! Michiko Kakutani> <he ceased to be a teacher as he became a
! text -- D. J. Boorstin>
! |
!
!
! Our Display Data type semantically remains to be text
! in the sense of Webster's definitions 5 b and
! 8. Clearly, word processor documents can contain images such as
! drawings or photographs. Modern documents can embed video sequences
! and animations as well. Dictation (audio) is the most important form
! of pre-written medical narratives. A scanned image of old medical
! records or of handwriting is certainly text. In this sense, almost
! everything can be text, which is also supported by the phenomenologic analysis given in the
! introduction.
!
2.1.5 Pulling the pieces together
In the previous exploration of the field of text, we separated out
the difference between string data elements, where the raw information
! of characters is sufficient and "display data," where there is use for
formatting the text and augment or even replace the text with
! multimedia information. This means that there will be a character string data type, and a display data type that covers character-based
! free text and multimedial data.
2.2 Character String
***************
*** 2473,2479 ****
|
! Character String
|
|---|
--- 2462,2468 ----
|
! Character String (ST)
|
|---|
***************
*** 2887,2911 ****
! 2.3 Free Text
To cope with the various encoding formats of appearance, there will
! be only one data type for free text. This type will have essentially
! two semantic components: It will (1) contain the free text data and
! (2) specify the application which can render that free text data. The
! application to render the data will be specified by a media type code,
! similar to the Internet MIME standard [cf. RFC 2046] or
! HL7 v2.3's ED data type. The only problem is what data type to use
! for the free text data.
Some formatted text could be defined on top of string data. Due to
the backwards compatibility of Unicode to ASCII and ISO Latin-1, the
! simple typewriter-style formatting, the troff escape sequences that
! were used by HL7's old data type FT and HTML/SGML formatting is
! possible on top of Unicode strings. In addition to the string data, we
! have to indicate the formatting method that should be used by the
! receiver to render a given string correctly.
Most proprietory text formatting tools, however, do not fit in the
character string, because those application use their own
--- 2876,2903 ----
!
! 2.3 Display Data
To cope with the various encoding formats of appearance, there will
! be only one data type for both character-based free text and
! multimedia data. This type is called "Display Data" and will have
! essentially two semantic components: It will (1) contain the data
! component and (2) specify the application which can render that data.
! The application to render the data will be specified by a media type
! code, similar to the Internet MIME standard [cf. RFC 2046] or
! HL7 v2.3's ED data type. The only problem is what data type to use for
! the data component.
Some formatted text could be defined on top of string data. Due to
the backwards compatibility of Unicode to ASCII and ISO Latin-1, the
! simple typewriter-style formatting, the TROFF
! escape sequences that were used by HL7's old data type FT and
! HTML/SGML formatting is possible on top of Unicode strings. In
! addition to the string data, we have to indicate the formatting method
! that should be used by the receiver to render a given string
! correctly.
Most proprietory text formatting tools, however, do not fit in the
character string, because those application use their own
***************
*** 2931,2976 ****
It therefore seem reasonable to define a data type for raw byte
strings to complement the character string data type. The raw byte
! type would be used only by the data type for free text, though. There
! is hardly any use case for HL7 application domain Technical Committees
! to use byte string data types directly.
! Using byte strings instead of character strings for free text is
not only a good idea for proprietory application data or multimedia
data, but is also supported by a closer look to standards such as
! HTML, SGML or troff. While those formats are defined on a notion of
! characters instead of bytes, the applications that implement HTML,
! SGML or troff, have their own means to interpret byte streams as
! character encodings (e.g. HTML has a META element and XML
! defines the character set in its !XML header
! element. More traditional formatting with troff is not even able to
! handle the full abstraction of characters that comes with Unicode and
! thus is also based on byte strings rather than character strings.
!
! As a conclusion, we can uniformly define the free text / multimedia
! data type as the pair of media type selector and raw byte data. If the
! sender does not want to use any of the format options for free text
! but just wants to send the raw characters, he can indicate this with a
! special media type (text/plain). It seems justified to
! make the plain text media type the default.
! 2.3.1 Multimedia Enabled Free Text
! The multimedia-enabled free text data type consists of the following
! components:
|
! Free Text
|
|---|
|
! The free text data type can convey any data that is primarily meant to
! be shown to human beings for interpretation. Free text can be any kind
! of text, whether unformatted or formatted written language or other
! multi media data.
|
| component name |
--- 2923,2981 ----
It therefore seem reasonable to define a data type for raw byte
strings to complement the character string data type. The raw byte
! type would be used only by the Display Data
! type, though. There is hardly any use case for HL7 application domain
! Technical Committees to use byte string data types directly.
! Using byte strings instead of character strings for display data is
not only a good idea for proprietory application data or multimedia
data, but is also supported by a closer look to standards such as
! HTML, SGML or TROFF. While those formats are
! defined on a notion of characters instead of bytes, the applications
! that implement HTML, SGML or TROFF, have their
! own means to interpret byte streams as character encodings (e.g. HTML
! has a META element and XML defines the character set in
! its <?XML encoding=...?> processing
! instruction element. More traditional formatting with TROFF is not even able to handle the full abstraction
! of characters that comes with Unicode and thus is also based on byte
! strings rather than character strings.
!
! As a conclusion, we can uniformly define the display data type as
! the pair of media type selector and raw byte data. If the sender does
! not want to use any of the format options for display data but just
! wants to send the raw characters, he can indicate this with a special
! media type (text/plain). Since the display data type is
! most commonly used for character-based free text, the plain text media
! type is the default.
!
! 2.3.1 Display Data
!
! Editorial Note: In previous releases
! of this draft specification this data type was called "Multimedia
! Enabled Free Text" or "Free Text" and was abbreviated "FTX." The name
! change to "Display Data" was strongly suggested because of
! considerable confusion caused by term "text" applied to multimedia
! data. In spite of the drastical name change the functionality of this
! data type has not changed at all.
!
! The display data type supports both character-based free text and
! multimedia data and consists of the following components:
|
! Display Data (DD)
|
|---|
|
! The display data type can convey any data that is primarily meant to
! be shown to human beings for interpretation. Display data can be
! character-based free text, whether unformatted or formatted, as well
! as all kinds of multimedia data.
|
| component name |
***************
*** 2985,2998 ****
optional
defaults to text/plain |
! used to select an appropriate method to render the free text data
|
| data |
Binary Data |
required |
! contains the free text data as raw bytes
|
| compression |
--- 2990,3003 ----
optional
defaults to text/plain |
! used to select an appropriate method to render the display data
|
| data |
Binary Data |
required |
! contains the display data as raw bytes
|
| compression |
***************
*** 3020,3027 ****
Other components may be defined for certain media types. This
! serves as a way to map MIME media type "parameters" to this Free Text
! data type. An example is the charset component, which is a
parameter of the MIME media type text/plain.
The media type descriptor of MIME
Other components may be defined for certain media types. This
! serves as a way to map MIME media type "parameters" to this Display
! Data type. An example is the charset component, which is a
parameter of the MIME media type text/plain.
The media type descriptor of MIME maintained by IANA.
Any of the IANA defined media types is in principle allowed for use
! with the Free Text data type. But not all media types have the same
status in this specification.
The following top level media types are currently defined by the IANA:
--- 3046,3052 ----
data base
maintained by IANA.
Any of the IANA defined media types is in principle allowed for use
! with the Display Data type. But not all media types have the same
status in this specification.
The following top level media types are currently defined by the IANA:
***************
*** 3059,3125 ****
behavioral or physical representation within a given domain" [RFC 2077]
- This data type is called Free Text , and so it
- seems strange, almost frightening, that the above list contain media
- types like video, application, even
- message. Should there not rather be one data type
- only for written text, one for audio, one for image, one for
- video, etc.?
-
- The rationale that lead to the definition of the free text data
- type is that free text is information sent from one human being to
- another human being. The receiving human being will - if she has a
- method to render and see the information - be able to interpret this
- data. To understand the full range of meaning of the word "text" we
- should have a look into Webster's
- dictionary:
-
-
- Main Entry: text
- Pronunciation: 'tekst
- Function: noun
- Etymology: Middle English, from Middle French texte, from
- Medieval Latin textus, from Latin, texture, context, from
- texere to weave -- more at TECHNICAL
- Date: 14th century
- 1 a (1) : the original words and form of a written or
- printed work (2) : an edited or emended copy of an original
- work b : a work containing such text
2 a
- : the main body of printed or written matter on a page b
- : the principal part of a book exclusive of front and back
- matter c : the printed score of a musical
- composition
3 a (1) : a verse or passage of Scripture
- chosen especially for the subject of a sermon or for authoritative
- support (as for a doctrine) (2) : a passage from an
- authoritative source providing an introduction or basis (as for a
- speech) b : a source of information or
- authority
4 : THEME,
- TOPIC
5 a : the words of
- something (as a poem) set to music b : matter chiefly in
- the form of words that is treated as data for processing by
- computerized equipment <a text-editing
- typewriter>
6 : a type suitable for printing
- running text
7 : TEXTBOOK
-
8 a : something
- written or spoken considered as an object to be examined, explicated,
- or deconstructed b : something likened to a text <the
- surfaces of daily life are texts to be explicated --
- Michiko Kakutani> <he ceased to be a teacher as he became a
- text -- D. J. Boorstin>
- |
-
-
- This multimedia data type remains to be text in the
- sense of Webster's definitions 5 b and 8. Clearly, word
- processor documents can contain images such as drawings or
- photographs. Modern documents can embed video sequences and animations
- as well. Dictation (audio) is the most important form of pre-written
- medical narratives. A scanned image of old medical records or of
- handwriting is certainly text. In this sense, almost everything can be
- text, which is supported also by the phenomenologic analysis given in the
- introduction.
-
There are currently more than 160 different MIME media subtypes
defined with the list growing quite fast. It makes no sense to list
them all here. In general, all those types defined by the IANA may be
--- 3064,3069 ----
***************
*** 3265,3274 ****
|
image/gif | other |
GIF is a nice format that is supported by almost everyone. But it
is patented, and the patent holder, Compuserve, has initiated nasty
! lawsuits in the past. No use to discourage this format, but we can not
! raise an encumbered format to a mandatory status. |
image/jpeg | mandatory
for high
color images |
--- 3209,3222 ----
image/gif | other |
+
GIF is a nice format that is supported by almost everyone. But it
is patented, and the patent holder, Compuserve, has initiated nasty
! lawsuits in the past [ The GIF
! Controversy: A Software Developer's Perspective]. No use to
! discourage this format, but we can not raise an encumbered format to a
! mandatory status. |
image/jpeg | mandatory
for high
color images |
***************
*** 3309,3317 ****
macromolecules)
multipart | deprecated | This
! major media type depends on the MIME standard, the Free Text data type
! uses only want to use MIME multimedia type definitions, not the MIME
! message format |
message | deprecated | This
major media type this is used to encapsulate e-mail messages in
--- 3257,3265 ----
macromolecules) |
multipart | deprecated | This
! major media type depends on the MIME standard, the Display Data type
! uses only MIME multimedia type definitions, not the MIME message
! format |
message | deprecated | This
major media type this is used to encapsulate e-mail messages in
***************
*** 3320,3333 ****
and HL7 is not used for e-mail. |
! Constraints may be applied on the media types whenever a Free Text
! data type is used, whether at the time of HL7 message specification,
or for a given application conformance statement, and even in the
RIM. For instance, suppose the Image Management SIG will eventually
define a class "Image". This class Image would
conceivably contain an attribute, "image_data", declared
! as Free Text. The IMSIG certainly would not want to see written text or
! audio here, but only images (and maybe a video clip of a coronary
angiography.)
--- 3268,3281 ----
and HL7 is not used for e-mail. |
! Constraints may be applied on the media types whenever a Display
! Data type is used, whether at the time of HL7 message specification,
or for a given application conformance statement, and even in the
RIM. For instance, suppose the Image Management SIG will eventually
define a class "Image". This class Image would
conceivably contain an attribute, "image_data", declared
! as Display Data. The IMSIG certainly would not want to see written text
! or audio here, but only images (and maybe a video clip of a coronary
angiography.)
***************
*** 3339,3345 ****
|
! Binary Data
|
|---|
--- 3287,3293 ----
|
! Binary Data (BIN)
|
|---|
|
***************
*** 3350,3356 ****
| PRIMITIVE TYPE |
|---|
! The data component of the Free Text data type is
not a character string but a block of raw bits. ASN.1 calls
this an "octet-string," which is the same as a "byte-string." The
important point is that the byte string would not be subject
--- 3298,3304 ----
| PRIMITIVE TYPE |
|---|
! The data component of the Display Data type is
not a character string but a block of raw bits. ASN.1 calls
this an "octet-string," which is the same as a "byte-string." The
important point is that the byte string would not be subject
***************
*** 3429,3436 ****
We will define a code for compression algorithms.
We recognized that there will be a reference data type defined to
! be used alternatively for huge data blocks. Should the free text type
! be allowed to be replaced by a reference, or should it contain a
reference?
Video streams do not fit into a single message, an external stream
--- 3377,3384 ----
We will define a code for compression algorithms.
We recognized that there will be a reference data type defined to
! be used alternatively for huge data blocks. Should the Display Data
! type be allowed to be replaced by a reference, or should it contain a
reference?
Video streams do not fit into a single message, an external stream
***************
*** 3729,3735 ****
! | Code Value |
|---|
|
A code value is exactly one symbol in a code system. The meaning of
the symbol is defined exclusively and completely by the code system
--- 3677,3683 ----
! | Code Value (CV) |
|---|
|
A code value is exactly one symbol in a code system. The meaning of
the symbol is defined exclusively and completely by the code system
***************
*** 3837,3843 ****
The above conversion rule allows to build concise messages with
code values, just like the HL7 v2.x ID data type allowed one to do.
! 3.2.1 Outstanding Issues
The code system obviously is by itself a
technical concept identifier. If we are going to use the
--- 3785,3791 ----
The above conversion rule allows to build concise messages with
code values, just like the HL7 v2.x ID data type allowed one to do.
! Outstanding Issues
The code system obviously is by itself a
technical concept identifier. If we are going to use the
***************
*** 3911,3922 ****
from the version id used by the other organization.
Unregistered local coding schemes have been the cause of a lot of
! trouble in the past. Laboratories, whose main concern is not HL7
update their code system ids quite frequently and without caring for
backwards compatibility. This places a lot of burden on the shoulders
of HL7 communication system managers. This burden would not be easier,
but heavier, if every ideolectic coding scheme that changes ever so
! often would have be registered with HL7.
The answer could be to say that locally defined coding systems do
not have any meaning outside the defining organization. Thus, there is
--- 3859,3870 ----
from the version id used by the other organization.
Unregistered local coding schemes have been the cause of a lot of
! trouble in the past. Laboratories whose main concern is not HL7,
update their code system ids quite frequently and without caring for
backwards compatibility. This places a lot of burden on the shoulders
of HL7 communication system managers. This burden would not be easier,
but heavier, if every ideolectic coding scheme that changes ever so
! often would have to be registered with HL7.
The answer could be to say that locally defined coding systems do
not have any meaning outside the defining organization. Thus, there is
***************
*** 3931,3944 ****
would be a digit. We can loosen this constraint a little bit by saying
that every code system name starting with "99" be local.
3.3 Real World Concepts
The old CE data type and its interim proposed successors (with
various names LCE/CWE and CE/CNE) were basically one pair of Code Value plus a free text string that could be
! used to convey the original text in an uncoded fashion.
The new data type for real world concepts is essentially a
generalization the CE. The Concept Descriptor is defined as a
--- 3879,4336 ----
would be a digit. We can loosen this constraint a little bit by saying
that every code system name starting with "99" be local.
+
+ 3.2.1 State of a State Machine
+
+ One particular kind of technical concept identifier will occur very
+ often in HL7 messages: state. Since the HL7 version 3 message design
+ methodology bases the definition of messages on State-Transition
+ models, the communication of state attributes will be standardized and
+ stylized.
+
+ The notion of a State of a State-Machine will not be defined here
+ in all detail, instead we refer to the HL7 Message Development
+ Framework, to the Unified Modeling Language Specification, and to a
+ vast amount of literature on that matter. Note that the study of
+ Automata (State-Transition-Models) is one of the oldest areas of
+ Computer Science and a basic part of computer literacy.
+
+ Objects have identity and state. Identity is fixed by an identifier
+ attribute of an object (or a reference to an object). An object is in
+ one and only one state at any time. The state is the total of all the
+ current values of attributes and all the current associations to other
+ object. Thus, generally speaking, state is far more than could be
+ represented in one state variable; in other words, the state of an
+ object is everything but its identity.
+
+ A State-Transition model often focuses at certain distingushed
+ features of an objects possible states. Thus, in a more narrow sense,
+ state variables explicitly capture those states of an object that are
+ defined in the State-Transition model of a class. Every state of a
+ State-Transition model stands for an entire class of actual states
+ that objects might go through in their life-cycle.
+
+ Many of such states defined by a State-Transition model will have
+ certain constraints that constrain the attributes and association that
+ must exist or that may not exist for an object in that defined state.
+
+ In the following we will use the term joint state to talk
+ about the overall state of an object according to a State-Transition
+ model. Note that at any given time an object is in one and only one
+ joint state, independent of the details of the State-Transition models
+ (e.g., no matter whether there are parallel sub-state-machines, or
+ nested state's used.)
+
+ We will use the term partial state to refer to the
+ sub-states that a State-Transition model distinguishes
+ individually. An object can be in multiple partial states at the same
+ time. The total of all partial states that are effective for an
+ object at any given time is the joint state for that object at
+ that time. Note that, generally speaking, all properties of an object
+ can be considered partial states, however, here we call partial states
+ (proper) only those partial states that are defined in the
+ State-Transition model.
+
+
+
+
+ 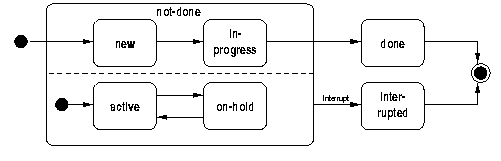 |
+ | Figure 3: Example State-Transition model. |
|---|
+
+
+ For a very simple State-Transition model in UML there may be no
+ difference between partial states and joint states. However, in UML
+ concurrent State-Machines partial states are different from joint
+ states. For example, an order may be in the states new,
+ in-progress and done, as shown in Figure 3. At the same
+ time any order may be active or on-hold. Suppose that
+ transitions to put an order on hold are considered independent from
+ the other three possible states of an order. In that case, the joint
+ state of the order is described by mentioning one partial state of
+ {new, in-progress, done} and one of the states
+ {active, on-hold}. The set of all possible joint states
+ would be the cartesian product of the two sets of states:
+
+
+
+ | new | active |
+ | new | on-hold |
+ | in-progress | active |
+ | in-progress | on-hold |
+ | done | active |
+ | done | on-hold |
+
+
+
+ There is another variation of the term "state" distinguished by
+ UML: composite state (or nested state) vs. simple
+ state. Composite states are more coarse-grained states that one
+ may want to distinguish because a transition may be applicable to each
+ of the component-states nested within the composite state.
+
+ For example, one may want to allow an order in both of the states
+ new and in-progress to be interrupted. So, one might
+ define another state: interrupted and one transition from each
+ of the states new and in-progress. To express that there
+ is really no difference betweem new and in-progress for
+ the purpose of interrupting, one can define a super-state, e.g.,
+ called not-done, to nest both new and
+ in-progress. Thus, only one "interrupt"-transition would be
+ used from the super-state.
+
+ State-Transition diagrams that use nested states are easier to read
+ and comprehend, since they provide abstratctions and generalizations
+ and thus reduce the number of similar transitions. However, the
+ information about super-states does not need to be mentioned
+ explicitly, since it is always implied by its component state. In our
+ example, if either new or in-progress is effective, we
+ know that the super-state not-done is also effective. Thus,
+ explicit information about super-states is always redundant.
+
+ Alternatives for designing a data type for state.
+
+ ISO 11404 (language-independent data types) defines a data type for
+ state. However ISO defines the state as a simple enumeration of state
+ code. Thus you could only communicate one symbol per joint state in a
+ variable of that type. If you have multiple parallel state machines,
+ in other words, if multiple partial states would be effective at the
+ same time, you would need to precoordinate the list of parallel state
+ codes.
+
+ Precoordination of the table of state codes for any given
+ class has its merits. With a precoordinated code, you know that any
+ given value is actually legal. Conversely, for a postcoordination of
+ codes, you do not know whether you have a legal combination unless you
+ explicitly test for it. In our example, in a precoordinated joint
+ state code you were sure noone could utter a state that at the same
+ time includes both in-progress and interrupted.
+
+ Precoordination, however, defers the burden to the time when the
+ information needs to be interpreted. A precoordinated code requires a
+ table that helps to separate the different partial states from the
+ joint state code. Even small changes to the state transition model may
+ entail a number of joint state codes to be added or taken away from
+ the table. On the other hand, if the processing of those state codes
+ were in reality based on a table, there is a lot of built-in
+ flexibility, since a table driven processor should continue to work
+ properly as the driving table is updated. So, a precoordinated state
+ code with one entry per joint state is a good choice.
+
+ Obviously the opposite of precoordination is
+ postcoordination and thus, we could define the state data type
+ as a vector of partial state code. If the possible partial state codes
+ can be factored into multiple orthogonal axes, it makes sense to label
+ each of the components of that vector of partial states with some
+ descriptive name, in other words, to represent state as one record
+ of joint states.
+
+ A related alternative to representing the joint state in one
+ attribute of a record type would be to allow the state to be expressed
+ in multiple attributes. An example for this is Wayne Tracy's
+ Clinical_document_header class with the four attributes completion
+ status, availability status, authentication status, and storage
+ status. Wayne's approach is currently not conformant with the MDF
+ style, however, Wayne's approach existed before the MDF style and that
+ has the honor of the elder, meaning it can not simply be dismissed as
+ a style guide violation. However, in the following I will stick to the
+ notion of a single state variable per object.
+
+ In a postcoordinated code for states the question arises what to do
+ with composite states. As noted above, composite states need
+ not be sent in a message since they are always implied by their
+ component states, thus, composite states are, strictly speaking,
+ redundant. However, just as mentioning the generalized composite
+ states in a State-Transition model simplifies definition of the model,
+ having the generalized states on hand might simplify the processing of
+ state information. Indeed, if all a given application is interested in
+ is a super-state to be effective, it is simpler to check for the
+ existence of that super-state flag in a collection of state flags,
+ rather than having to test for every possible sub-state flag.
+
+ In our example, the diagram says that the transition "interrupt" is
+ possible from the super-state not-done that encloses the
+ sub-states new or in-progress. It would be convenient
+ for an application to test whether not-done is among the set of
+ state flags in the state variable (one test), rather than to test
+ whether the either state new or in-progress is effective
+ (two tests).
+
+ The postcoordinated approach with explicit super-states also
+ simplifies seamless evolution. The following evolutionary developments
+ of State-Transition diagrams are supported:
+
+
+ Refinement of a state to include sub-states. This is probably
+ the most likely development. The scenario is that some applications
+ will know earlier than others that the state not-done would
+ have turned into a super-state containing new and
+ in-progress. Since the not-done state flag will be
+ continued to be sent in the state variable, old applications continue
+ to work, if they ignore the unknown state flags. Ignoring the unknown
+ state flags is quite natural, since one would rarely iterate over all
+ state flags in the state variable, rather than testing whether
+ particularly known state flags of interest are within the set.
+
+
+ "Recoarsement" (antonym of "refinement",) i.e. turning a
+ super-state with sub-states into a state without sub-states. This is
+ probably quite rare. It could occur if a we had an over-design in a
+ State-Transition model, providing features that nobody wants to use
+ and that cause more confusion than benefit. In this scenario, the
+ not-done state that had sub-states will turn into a state
+ withgout the sub-states. Since most (if not all) applications in this
+ scenario never asked for the sub-states and only tested for the
+ super-state, they will not even notice that the sub-states are no
+ longer defined in the model.
+
+
+ Introduction of a super-state. In our example, suppose our
+ state-transition diagram started without the not-done state and
+ two "interrupt" transition were defined from both new and
+ in-progress. The model would later be simplified to include
+ the state not-done with only one transition named "interrupt".
+ Note that the introduction of super-states is a very mild change, and
+ properly designed applications that conformed to the old model will
+ also be conformant to the new model. However, old applications
+ would not send the super-state flag explicitly in their state
+ variables, which could lead to problems with new applications that do
+ rely on that state-flag to be sent.
+
+
+ Introduction of parallel sub-state-machines. In our example,
+ suppose our State-Transition model did not contain the active -
+ on-hold sub-state-machine. The introduction of the new
+ parallel states will introduce new state flags in the state variable,
+ but applications that do not depend on those states will just ignore
+ them. In the reverse direction, new applications that do handle the
+ parallel state-machine, need to assume a default state active
+ if not otherwise mentioned.
+
+
+ Conversely, the pre-coordinated status code would have changed
+ significantly with every of the above changes and the kind of
+ flexibility we have with the post-coordinated code could be achieved
+ only with an intermediary table for interpretation and mapping between
+ message status codes and application status codes.
+
+ I have some UML issues that reinforce me to recommend
+ a little un-dogmatic UML modeling style, which however is not a big
+ difference. In UML a tranbsition from a super-state to one of it's
+ internal sub-states is not defined. Rather UML suggests to use nested
+ initial pseudo-states. However, this requires to explicitly mention
+ both states active and on-hold which is really
+ redundant. Having both states in the model is redundant because
+ active is considered just the negation of the on-hold
+ state and does not add any functionality or clarity to the model. The
+ evolution is easier if on-hold would just be added as a new
+ feature and the default being automaticly active, if on-hold
+ not being mentioned.
+
+ Finally another alternative is to use a post-coordinated state
+ code without mentioning super-states. On the first glance, the
+ above-mentioned evolution paths rely on the super-state information to
+ be sent. However, one tiny step of indirection in the interpretation
+ of the state variable would open the same evolution path for the
+ minimal set of state flags.
+
+ Remember that states are essentially predicates or assertions about
+ objects. The named states, e.g., new will be used in predicate
+ statements such as: "if state is new
+ do stuff," or more formally: "if new(state) do
+ stuff." How would those predicate tests be implemented?
+
+ If we had a precoordinated state code, or if we had only one state
+ flag at a time, the program would ask whether the current state equals
+ some state to test for:
+
+
+
+ IF state = new
+ THEN
+ do stuff
+ ENDIF
+
+
+
+ If you have to test for the state not-done if it is not sent
+ explicitly you need to do
+
+
+
+ IF ( state = new ) OR ( state = in_progress )
+ THEN
+ do stuff
+ ENDIF
+
+
+
+ If not-done is sent explicitly, the state variable can not be
+ just one code but a set of state flags. That is, the test would look
+ like
+
+
+
+ IF not_done IN state
+ THEN
+ do stuff
+ ENDIF
+
+
+
+ if the state variable were a set and super-states, such as
+ not-done were not mentioned, you had
+
+
+
+ IF ( new IN state ) OR ( in_progress IN state )
+ THEN
+ do stuff
+ ENDIF
+
+
+
+ or alternatively (with * being the intersection operator)
+
+
+
+ IF ( { new, in_progress } * state ) <> {}
+ THEN
+ do stuff
+ ENDIF
+
+
+
+ now, even if super-states would not be mentioned explicitly, we could
+ use a table of constants that let the application work the same no
+ matter whether super-states are mentioned explicitly or not:
+
+
+
+ CONST
+ new_mask := SET { new };
+ in_progress_mask := SET { in_progress };
+ not_done_mask := SET { new, in_progress };
+
+ ...
+
+ IF ( not_done * state ) <> {}
+ THEN
+ do stuff
+ ENDIF
+
+
+
+ The advantage of this method is that your application code is
+ invariant to whether states are represented explicitly or not.
+ In addition one can test for special state constellations such as
+ in-progress AND on-hold:
+
+
+
+ CONST
+ new_mask := SET { new };
+ in_progress_mask := SET { in_progress };
+ not_done_mask := SET { new, in_progress };
+ my_special_mask := SET { in_progress, on_hold };
+ ...
+
+ IF ( my_special_mask * state ) = my_special_mask
+ THEN
+ do stuff
+ ENDIF
+
+
+
+ As a conclusion, it seems to be very flexible to assume state variable
+ uniformly to be a set of state flags and to test for state flags
+ indirectly through intersections with "mask" sets testing for the
+ non-empty set (OR) or equality with the mask (AND).
+
+ In the same way one can conduct checks for the state variable to
+ represent a legal state, e.g., to test for either new
+ or in progress to be effective, but not both:
+
+
+
+ CONST
+ new_mask := SET { new };
+ in_progress_mask := SET { in_progress };
+ not_done_mask := SET { new, in_progress };
+
+ IF CARDINALITY( not_done_mask * state ) > 1
+ THEN
+ THROW Illegal_state_exception;
+ ENDIF
+
+
+
+ The set operations as shown in the above examples seem to require
+ special programming language support, however, in fact they do
+ not. Sets in Pascal or MODULA 2 are nothing but bit-fields, and the
+ intersection operator is nothing but the bit-AND operation on bit
+ fields. Thus this mechanism is implemented with ease on any
+ programming language such as C, BASIC, you-name-it.
+
+ To summarize the above discussion we have found:
+
+ that a pre-coordinated state code enforces only legal states to
+ be communicated, but interpretation and evolution is difficult and
+ requires a table to interpret and map state codes to something the
+ application can handle;
+
+ that a redundant post-coordinated state code, that sends
+ super-state information is easy to handle and allows for smooth
+ evolution and interoperability between applications with a different
+ interest in the details of a state-machine;
+
+ that a post-coordinated state code that does not send
+ super-state information is even more flexible given that state
+ predicates are tested based on state "masks" that can be defined
+ in a simple table.
+
+
+ that a pre-coordinated state code will always fit in a single
+ code value;
+
+ that a post-coordinated state code will rarely fit in a single
+ code value and treating it as a set up-front is a requirement for the
+ discussed evolution rules;
+
+ that a post-coordinated state code can alternatively be sent in
+ a record of state variables or in multiple state variables, in which
+ case the described flexibility of evolution and interpretation is
+ lost. [There are ways to consolidate multiple state variables in an
+ application, but that is more complex for the sole reason to have
+ multiple state variables in the RIM.]
+
+
+ No decision has been made as of yet. My proposal is to:
+
+ Define a data type called "State" which makes the actual state
+ representation opaque to the application layer. I don't want to bother
+ the domain TCs with this "CV or SET" discussion.
+
+ Stick to the MDF rule of one state variable and try to pursue
+ Wayne that this would work for his part of the standard. However, wait
+ with making the final decision until Wayne has agreed to the
+ harmonization proposal to merge his four state-variables into
+ one. Wayne has the right of the elder here.
+
+ Use the non-redundant post-coordinated state representation and
+ propose to implementors to test for states uniformly using
+ "masks". Alternatively to go to the redundant post-coordinated
+ alternative, if opposition gets too nervous.
+
+
+
3.3 Real World Concepts
The old CE data type and its interim proposed successors (with
various names LCE/CWE and CE/CNE) were basically one pair of Code Value plus a display data string that could
! be used to convey the original text in an uncoded fashion.
The new data type for real world concepts is essentially a
generalization the CE. The Concept Descriptor is defined as a
***************
*** 4005,4011 ****
|
! Concept Descriptor
|
|---|
--- 4397,4403 ----
|
! Concept Descriptor (CD)
|
|---|
|
***************
*** 4047,4053 ****
original text
|
! Free Text
|
--- 4439,4445 ----
original text
|
! Display Data
|
***************
*** 4070,4076 ****
|
! Code Translation
|
|---|
--- 4462,4468 ----
|
! Code Translation (CDXL)
|
|---|
|
***************
*** 4151,4157 ****
quality
|
! Floating
Point
Number
[0..1]
|
--- 4543,4549 ----
quality
|
! Real
Number
[0..1]
|
***************
*** 4178,4184 ****
|
! Code Phrase
|
|---|
--- 4570,4576 ----
|
! Code Phrase (CDPH)
|
|---|
|
***************
*** 4559,4564 ****
--- 4951,4963 ----
of ways for people to abuse its power and hardly any idea about how to
use the power properly.
+ Note that from the SNOMED camp there is probably support for an
+ even more complex definition of the Code Phrase that would basically
+ be a keyword-value structure containing small conceptual
+ graphs. [cf. Spackman KA. Compositional concept representation using
+ SNOMED: towards further convergence of clinical terminologies. Proc
+ Annu Symp Comput Appl Med Care. 1998 Oct. p. 740-4.]
+
3.4 Technical Instances
***************
*** 4747,4753 ****
|
! Technical Instance Identifier
|
|---|
--- 5146,5152 ----
|
! Technical Instance Identifier (TII)
|
|---|
***************
*** 4890,4896 ****
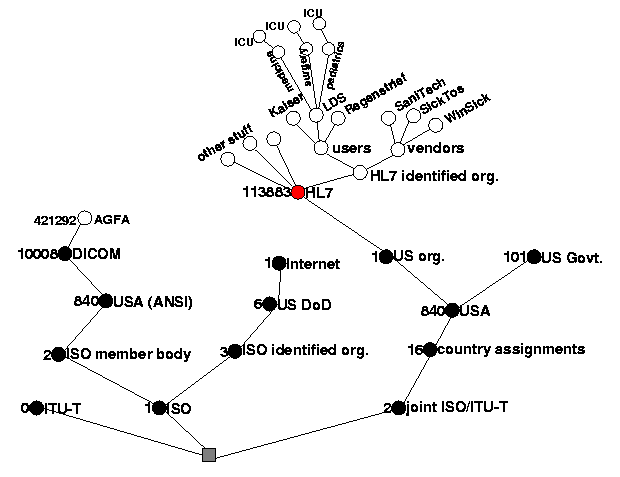 |
! | Figure 3: The the hierarchy of ISO Object Identifiers and how
it could be used by HL7. |
|---|
--- 5289,5295 ----
|
! | Figure 4: The the hierarchy of ISO Object Identifiers and how
it could be used by HL7. |
|---|
***************
*** 5043,5060 ****
3.4.3 Technical Instance Locator
! Another data type of technical instance identifiers is dereferencable
! identifiers, or "locators". The Technical Instance Locator (TIL) is
! shaped similar to Universal Resource Locator (URL). That
! is TIL has the two components protocol and address where
! the format of address would be determined only by the
! protocol. Telephone number, e-mail address, and the locator for the
! reference pointer type would be of this data type.
|
! Technical Instance Locator
|
|---|
--- 5442,5460 ----
3.4.3 Technical Instance Locator
! Another kind of data type for technical instances is the Technical
! Instance Locator (TIL), which is a dereferencable identifiers,
! reference, or (technical) address. The Technical Instance Locator
! (TIL) is shaped similar to Universal Resource Locator
! (URL). That is TIL has the two components protocol and
! address where the format of address is determined by the
! protocol. Telephone number, e-mail address, and the locator for an
! image reference pointer would be of this data type.
|
! Technical Instance Locator (TIL)
|
|---|
***************
*** 5156,5162 ****
:address "+13176306962")
-
3.4.4 Outstanding Issues
We will still define as successor of the reference pointer (RP) to
--- 5556,5561 ----
***************
*** 5164,5176 ****
the thing that is referred. This would also include an expiry date
after which the locator can not be expected to be usable.
3.5 Real World Instances
! We refer to things in the "real world" generally by giving them
names. Assigning names to people, things and places are a public acts:
the more people know some name, the more will later understand what is
! meant by some name. In archaic cultures, knowing the name of something
meant having some power over it. Indeed, knowledge is power and
without a name, we can not talk about things, we can barely think of
things, and we can not collect knowledge about them. The record
--- 5563,5586 ----
the thing that is referred. This would also include an expiry date
after which the locator can not be expected to be usable.
+ The use of the TIL for phone numbers needs more explanation and
+ rationale.
+
+ The TIL may need to be wrapped in a History.
+
+ The TIL may need some "use code", to capture the qualifiers
+ "business", "home", "cellphone", etc. for phone numbers. How does this
+ "use code" generalize to other communication addresses? Why is it
+ needed?
+
+
3.5 Real World Instances
! We generally refer to things in the "real world" by giving them
names. Assigning names to people, things and places are a public acts:
the more people know some name, the more will later understand what is
! meant by that name. In archaic cultures, knowing the name of something
meant having some power over it. Indeed, knowledge is power and
without a name, we can not talk about things, we can barely think of
things, and we can not collect knowledge about them. The record
***************
*** 5224,5244 ****
locations tend to be extremely stable over a long period of time
determines the structure of the address kind of names. Addresses
determine locations by stepwise refinement of a scope (country - city
! - street - house - floor). Most scope-name has all the characteristics
! of names, i.e. arbitrarily assigned, non-descriptive, not
! unique. Apart from scope refinement all kinds of spacial descriptors
! can be part of an addres (e.g. right hand side, opposite side.)
3.5.1 Real World Instance Identifier
- Note: This section is a proposal of the Data Type working
- group and still needs to be negociated with PAFM.
-
External identifiers for real world people and things occur
! frequently. Examples for people identifiers are Social Security
! Number, Driver License Number, Passport Number, Individual Taxpayer
Identification Number. Identifiers for organizations are, e.g., the
federal identification number or the Employer Identification Number.
The current approach in the RIM is to use the Stakeholder_identifier
--- 5634,5652 ----
locations tend to be extremely stable over a long period of time
determines the structure of the address kind of names. Addresses
determine locations by stepwise refinement of a scope (country - city
! - street - house - floor). Most scope-names have all the
! characteristics of names, i.e. arbitrarily assigned, non-descriptive,
! not unique. Apart from scope refinement all kinds of spacial
! descriptors can be part of an addres (e.g. right hand side, opposite
! side, north, east, etc.)
3.5.1 Real World Instance Identifier
External identifiers for real world people and things occur
! frequently. Examples for people identifiers are Social Security Number
! (SSN), Driver License Number, Passport Number, Individual Taxpayer
Identification Number. Identifiers for organizations are, e.g., the
federal identification number or the Employer Identification Number.
The current approach in the RIM is to use the Stakeholder_identifier
***************
*** 5247,5262 ****
Here are some of those identifiers used in the U.S.
! - SSN used as a legal individual person identifier
- ITIN (Individual Taxpayer Identification Number), like an SSN but
! issued by IRS for aliens not eligible for an SSN.
!
- EIN (employer identification number) used by IRS for organizations
!
- FIN (Federal Identification Number?) for corporations
!
- DLN (Driver License Number). U.S. driver licenses are issued by
! the states. Driver licenses in the U.S. are used as identity cards.
!
- The "Universal" (meaning "U.S.American") Health Identifier - if
! it will ever come.
!
- Health Care Provider Identification Number (?)
- Passport Number
--- 5655,5683 ----
Here are some of those identifiers used in the U.S.
! - Social Security Number (SSN and ITIN) - for U.S. persons;
!
!
- Employer Identification Number (EIN) - for U.S. corporations;
!
- ITIN (Individual Taxpayer Identification Number), like an SSN but
! issued by IRS for aliens not eligible for an SSN;
!
!
- Driver License Number (DLN) - for U.S. residents, are issued by
! the states, U.S. are used as identity cards.
!
!
- HIPAA Provider Identification Number - for U.S. healthcare provider
!
!
- HIPAA "Universal" (meaning "U.S.American") Health Identifier - if
! it will ever come.
!
!
- Inventory Numbers - for desks, computers, and coffee makers in
! everyone's office
!
!
- Credit Card Numbers - for people and their CC accounts
!
!
- Medical Record Numbers - for a patient as the subject of a medical
! record
!
- Passport Number
***************
*** 5270,5665 ****
pretty reliable person identifier. Banks and employers must collect
the SSN of their customers and employees (resp.) for tax purposes.
! However, there are other such identification numbers, not issued
! for persons. Those numbers have basically the same semantics and the
! same requirements, except that those numbers might be assigned for
! real world instances other than people or organizations. Examples are
things, such as devices and durable material (inventory numbers), lot
numbers, etc.
! The public health / animal proposal, for example, has a concrete
! need for the following identification numbers:
!
! - lip tattoo - horses
!
- leg tattoo - dogs
!
- ear tags - food animals
!
- microchips - all species
!
- breed registry number - dogs
!
- jockey club - thoroughbred horses
!
- quarterhorse association
!
- US trotting association
!
- Holstein association regsitry - cows
!
! Such real world instance identifiers are assigned not only by big
! organizations but also by smaller organizations. For example,
! virtually every organization puts tags with numbers on their
! inventory.
! Medical Record Numbers (MRN) as used in the world of Paper Medical
! Records are another example for such real world instance
! identifiers. Note that in the computer world, we would not need MRNs,
! since we could use Technical Instance
! Identifiers (TII) to refer to computerized medical
! records. However, Wes Rishel and I think that as a rule of thumb, TIIs
! should not be communicated through human middlemen in order to keep
! reliability in their correctness high. Thus, as long as MRNs are typed
! in by clerks and other people, one should separate them from TIIs.
- The basic structure of such a real world instance identifier is:
!
!
!
! | value |
! CharacterString |
! the identifier value itself |
!
!
! | validity period |
! Interval OF PointInTime |
! covers effective date and expiration, begin and end date/time,
! etc. |
!
!
! | kind |
! Code Value |
! A rough classification telling you what kind of identifier
! this is (e.g. SSN, DLN, Passport, inventory, etc.)
! |
!
!
! | assigning authority |
! ? |
! An organization that has authority over and issued an identifier. |
!
!
! | name space |
! ? |
! An organization may maintain
! different name spaces without necessarily creating organizational
! subdivisions. Thus one assigning authority may maintain multiple name
! spaces.
! |
!
!
! The main methodological question is how we represent the identifier
! assigning authority. This would usually be an organization, and hence
! would an issuing authority be represented by an association to the
! Organization class. This is basically what the Stakeholder_identifier
! class does in RIM 0.88.
!
! However, this is also a problem. We are able to carry quite a lot
! of information about the identifier assigning authority, which is
! good. But the structure is rather complex, which is bad. Particularly,
! while we all know that SSN, DLN, etc are issued by organizations, we
! do not care so much about that organization. The only thing we want to
! know is that a given number is an SSN.
!
! However, things become tricky if we try to shortcut. The problem is
! that SSN and DLN are valid in realms defined by the issuing
! authorities. For example, for a DLN we need to know the state. For an
! SSN in an international context, we need to know the country.
!
! With a mandatory link to an assigning authority, an Indiana drivers
! license would be represented as having the "Indiana Bureau of Motor
! Vehicles (BMV)" as an issuing authority. This is troublesome because
! someone in California might not know that there is a BMV in
! Indiana. The BMV, of course, is an affiliate of the state of Indiana,
! but communicating this as a super-organization may be too much. In
! international contexts do, we would have to go once more through the
! stakeholder-affiliate loop so that the receiver can find out that
! Indiana is actually a part of the U.S. While this may be the correct
! solution, it seems to be rather impractical.
! The following principle options exist:
!
! Association with stakeholder (or organization) as the assiging
! authority. A clean, but somewhat verbous heavy weight way, as
! described.
!
!
! | Real World Instance Identifier (RWII) |
! | value | CharacterString |
! | authority | reference to Organization |
!
!
! In this alternative we pointing out to an Organization class
! instance from inside the data type? This is a weird construct that we
! have never seen before in the world of the RIM vs. Data Types
! dichotomy.
!
! The Organization as an assigning authority would itself have
! one or more RWIIs. Thus, one represent the assigning authority
! recursively as a RWII.
!
!
! | Real World Instance Identifier (RWII) |
! | value | CharacterString |
! | authority | RWII |
!
!
! This is a specific way to make the reference to an assigning
! authority Organization, i.e. by looking up the organization through
! its RWII.
!
! An OID for assigning authority, which structurally renders the
! RWII similar to the TII but with a very different
! semantics.
!
!
!
! This alternative, while structurally similar to the TII is in fact very different. The TII is
! supposed to be globally and dependably unique. This dependable
! uniqueness, can not be required from real world identifiers, that are
! ofthen reported orally or on paper. Morover, such numbers are often
! reused either accidentially (roll-over of counters) or voluntarily
! (old number considered outdated).
!
! The traditional way to represent assiging authority would be
! through a single "code" from some "master table"
!
!
!
! Options 3 and 4 are seemingly simple but they do lead to
! practicability problems: They don't scale. The OID is pseudo-unique
! and not meaningful (e.g. what is the OID of the state of Indiana?) In
! both options 3 and 4 you have to interpret the authority part from
! some unknown table or directory. This would not be a real problem if
! RWIIs would only be such official things as SSN, ITIN, EID, FID, DLN,
! etc. But the traditional medical record numbers are assigned
! locally. Also Inventory numbers for devices are assigned locally.
!
! Options 2 through 4 use various schemes of forreign keys to refer
! to organizations, which violates the MDF rules that forreign keys must
! be turned into explicit associations. Alternative 1 is principally
! open to whether or not forreign keys are used, but if Datatypes are
! considered different from RIM classes the question is how such an
! association from a data type to a RIM class could be made?
!
! Regardless whether the MDF deprecate forreign keys, this identifier
! data type "wants to be a forreign key" (as Mark Tucker puts it.)
! Indeed, this data type embodies the fact that we use "keys" in order
! to refer to things accross (foreign) models.
!
! Mark Tucker further offered the following "trick" to make
! alternative 4 useable and - to a certain extent - interoperable:
! People could use use local codes for assiging authorities within their
! usual communication horizon, assuming that master tables would be
! synchronized. For outside communication, a "row" of such a master
! table could just be included in the message. This master table row
! would be used to map "strings" to "things".
!
! This allows for very short forms of identifiers, which is
! good. Conversely, representing assiging authority as an Organization
! instance (alternative 1) would lead to ugly lengthy messages.
!
! However, two problems arise:
!
! It is not guarranteed that the strings for assigning authorities
! wouls be unioque within a message.
!
! How would we represent this "master file" construct?
!
! The Stakeholder hierarchy basically is such a master file
! structure. Thus the question is why we would represent associations to
! "master" stuff differently for this data type than for all other RIM
! classes?
!
! There is no easy way out of this dilemma, which suggests to put
! this Real World Instance Identifier "data type" as a class directly
! into the RIM. This allows the "data type" to associate with other
! classes, such as organization. From this "data type" we can define
! CMETs and we can implement those on ITSs however we like, i.e. we do
! not have to rely on a stereotypic automatism to derive lengthy ITS
! representations when a short form would be more exonomical and more
! pleasing to the "look and feel" of the message.
!
! There is a number of RIM changes pending that need a discussion and
! vote jointly with PAFM and CQ in the upcoming HL7 meeting (Toronto.)
! Figure 4 shows the structure around
! Stakeholder_identifier as of RIM 0.88.
!
!
!  |
! | Figure 4: Stakeholder_identifier as of RIM 0.88t. |
|---|
!
! The changes in detail are as follows:
! PAFM
!
! - PAFM (Richard Ohlmann) suggested to pass Stewardship of the
! Stakeholder_identifier class over to Control/Query.
!
!
Rationale: this class will undergo a broadening of scope. PAFM
! therefore no longer has to take the burden of maintaining this class
! for everyone else. That's what Control/Query is for.
!
! CQ
!
! - Rename class "Stakeholder_identifier" to
! "Real_world_instance_identifier".
!
!
Rationale: to signify the broadening of this classe's scope.
!
! - Rename attribute "id" to "value" in order to disambiguate this
! attribute from a technical instance identifier.
!
!
- Assign Data Type Character String (ST) to the attribute "value".
!
!
- Rename Attribute: "effective_dt" to "validity_period".
!
!
- Assign Data Type: "Interval of Point in Time" to attribute
! validity_period.
!
!
- Delete Attribute: termination_dt
!
!
Rationale: the two attributes effective_dt and termination_dt were
! used to signify the validity period of the identifier. A period of
! time can more properly (and more compact) be represented by the new
! data type Interval of Point in Time. This allows for infinite as well
! as unknown begin and termination dates.
!
! - Delete Attribute: issued_dt
!
!
Rationale: it is unclear why date of issuing differs from effective
! date. There seems to be no usecase to me (PAFM folks: please confirm
! or defend!)
!
! - Delete Attribute: qualifying_information_txt.
!
!
Rationale: the use of this attribute is in part taken over by
! "namespace". Where it is not handled through namespace different
! assiging authorities should be used. This prevents the same
! information to be representable in different ways.
!
! Rename class: "Identifier_assigning_authority" to
! "Identifier_namespace"
!
! Definition: A list of identifiers owned and managed by an
! organization stakeholder. An organization that manages a name space is
! an identifier assigning authority.
!
! Remove all attributes.
!
! Rationale: This is no longer a role-class. Nobody could define the
! use case of the old role-class and the begin/end time attributes. It
! seems to have been created as modeling stereotype that was not uesful
! in practice.
!
! Add attribute "name" of type Character String (ST).
!
! Definition: The name of a namespace is a symbol that might be used
! as a short form for the namespace in messages. This accomodates the
! practice that assigning authorities are just kept in a table of
! symbols, without attaching any real information about the
! organization.
!
! Change role-names and multiplicities as shown in Figure 5.
!
! PAFM
!
! - Move Attribute: citizenship_country_cd from Person to Stakeholder.
!
!
Rationale: in an international use context of HL7 it is necessary
! to keep track of the "citizenship" of organizations as well as of
! individual persons.
! - Rename Attribute: "citizenship_country_cd" to "citizenship_cd".
!
Rationale: A shorter name is easier to read, write, speak and memorize.
! - Delete Attribute: "nationality_cd"
!
Rationale: The difference between citizenship and nationality is
! unclear, did not exist in HL7 v2.x, and thus, can be deleted.
! PAFM
! The following are suggestions for simplification of the stakeholder
! affiliation loop. These changes are not essential to the Control Query
! related requirements. Nevertheless, since the stakeholder affiliation
! loop would be used by all of Control Queries "customers" we have an
! interest in this to be as cumberless as possible.
!
! - Move Attribue: "family_relationship_cd" from Stakeholder_affiliate
! to Stakeholder_affiliation.
!
- Reroute Association: from Stakeholder_affiliation
! "secondary_participant" to attach directly at Stakeholder.
!
- Delete Class: Stakeholder_affiliate.
!
Rationale: This additional relationship class on the "secondary"
! leg of stakeholder affiliate was primarily a modeling stereotype of
! little known practical use. The familiary relationship can as well be
! carried by the stakeholder affiliate class where applicable. This
! leads to a model that is simpler to use and simpler to understand
! while maintaining the same level of expressiveness and explicity.
!
! - Delete Association loop "subdivision" at Organization.
!
!
Rationale: this subdividing of organizations is a kind of
! "affiliation" relationship, which would also be expresed by the
! "Stakeholder_affiliation" class. There should be only one way of
! expressing affiliations (including
! subdivision). Stakeholder_affiliation.family_relationship_cd should
! have a value reserved for subdivision of organizations. Note that
! affiliation_type code is to express the "purpose" of a particular
! affiliation (e.g. emergency contact), while family_relationship is the
! durable relationship between stakeholders throughout all purposeful
! affiliations.
!
! Others
!
! 21.New Association: classes that would have a real world
! instance identifier, such as, "Durable_medical_equipment" should be
! associated to the Real_world_instance_identifier class. To exemplify
! that the new class can be used not only to identify stakeholders but
! also things and animals.
!
! We can also reuse this data type in order to put the identifiers
! for stakeholders in their proper place in the model, instead of
! pushing them all up into the highest level of the hierarchy, i.e. the
! Stakeholder class.
!
! The following diagram shows the effect of the proposed changes.
!
!
!  |
! | Figure 5: The Stakeholder_Identifier has become the "Real
! World Instance Identifier" and is thus useful for other things, such
! as the inventory number of medical devices. |
|---|
! This is basically a stepwise RIM change as would be required for
! Harmonization. We will discuss this with PAFM and other affected
! technical committees at the next HL7 meeting (Toronto).
--- 5691,6053 ----
pretty reliable person identifier. Banks and employers must collect
the SSN of their customers and employees (resp.) for tax purposes.
! While many of such identifiers are assigned to people and
! organizations, what characterizes those numbers is not what they are
! assigned to, but who assigns them, how they are assigned, and how they
! are used. There is a need for such numbers to be assigned to real
! world instances other than people or organizations. Examples are
things, such as devices and durable material (inventory numbers), lot
numbers, etc.
! The following challenges exist for exchanging real world instance
! identifiers:
!
! - "Communication Horizon" - if you communicate an identification
! number in-house, there is usually good understanding and no ambiguity.
! For inter-institutional communication there is possible ambiguity in
! the primary identifiers and the secondary identifiers for assigning
! authorities.
!
- Information about assigning authorities is relevant or irrelevant
! depending on the scope of a message.
!
- Systematizing identifier types and usage in an international
! context is difficult.
!
! Organizations as assigning authorities
! The following kinds of organizations assign real world instance
! identifiers:
!
! - National governmental agencies (e.g., SSN, HCFA provider ID)
!
- State/Province governmental agencies (e.g., DLN)
!
- Professional organizations (e.g. AMA)
!
- Insurers, Banks, Credit Card Companies (e.g., Kaiser, BC/BS, VISA
! for their customers)
!
- Health provider organizations (e.g., Hospital Medical Record
! Numbers, Inventory Numbers.)
!
- Departments and other sub-organizations (e.g., special MRN rings for
! stat assignments.)
!
- non-formal units or task forces within an
! organization.(e.g. clinical trial enrollment number)
!
! Considering health provider organizations (as the main users of HL7
! messages,) we can distinguish three general cases where the assigning
! authority is treated slightly different:
! National and state agencies' numbers are "well known," e.g. nobody
! ever wants to see the address and phone # of the U.S. Social Security
! Administration (SSN) or the Indiana Bureau for Motor Vehicles (DLN) in
! an HL7 message.
!
! Moreover, the identifier types themselves are an "institution" much
! more important than the assigning authorities. For example, the SSN
! data field will often times contain Individual Taxpayer Identification
! Numbers (ITIN) that are compatible to SSNs but are assigned by the IRS
! rather than the SSA. The distinction between SSN and ITIN is tricky
! and mostly irrelevant for HL7 users.
!
! Professional organizations are usually treated as "well known." E.g.,
! if you have a doctor's medical license number valid for the U.S., you
! don't need to communicate the details of the issuing organization
! (e.g. AMA.)
!
! Insurers, Banks and Credit Card Companies are "third party"
! organizations that are external to health provider organizations. This
! means, most HL7 messages will want to add some minimal information
! about the assigning authority as an organization because those third
! party organizations are neither "well known" nor do they belong to any
! one provider organization.
!
! Provider organizations and their sub-units. These are the issuers
! of the vast majority of numbers communicated in everyday messaging.
! For all "in-house" messages, the assigning authority is the same or
! closely related to the HL7 user. So, there is no need to communicate
! much information about that organization.
!
! For external communication, however, the assigning organization needs
! to be identified with more detail. Generally, the less routinely
! messages are sent to a particular external recipient the more detail
! information about assigning authorities is appreciated.
!
! Finally there are cases where the same organization assigns different
! numbers of the same type. For example, patient identifiers are issued
! for routine care, but the same health care organization runs several
! clinical trials where patients get separate identifiers or enrollment
! numbers. Thus, the same organization that runs different trials will
! want to build partitions of the overall set of assigned identifiers
! (sub-namespaces.)
!
! Identifier types and their use
! We intuitively know that there are different types of identifiers and
! that we want to keep track of the identifier type. The first
! identifier type that comes to mind in a U.S. context is the Social
! Security Number (SSN). This example shows two difficulties that any
! "typology" of identifiers runs into and must deal with:
!
! Semantics (meaning) and pragmatics (use) of one type of identifier
! may be completely different and not even related. For example, the
! meaning of the SSN is that it identifies every U.S. person's social
! security record. But the SSN is only in 5% (estimated) of all uses
! cases related to a person's social security matters. Much more often
! (40%), the SSN is used as a person's taxpayer's identification number
! (by the IRS or by withholding agents, such as employers, banks, or
! mutual fund/IRA services.) Most health provider organizations use the
! SSN as a pretty good national person identifier (40%). In addition
! all kinds of companies collect SSNs from their customers for various
! purposes.
!
! Identifier type concepts do not easily translate between
! different realms (e.g. countries.) Take Social Security Numbers (SSN)
! for example: most countries that have a nationally organized social
! security system will have social security numbers. However, as noted
! above, the purpose of collecting SSNs in the U.S. health care industry
! is not social security, but person identification. Germany has SSNs
! too, but nobody uses the German SSN as a general person identifier.
! German SSNs are exclusively used in communications with the German
! social security administration about genuine social security
! issues.
!
! The same case can be made for the Driver License Number. In Europe,
! driver licenses are primarily used as a certification to run a motor
! vehicle, and thus in 90% of the cases shown to police officers and
! highway patrols. In the U.S. the situation is completely different:
! here, more than 50% of driver license checks occur in bars and night
! clubs to gain entrance and to be served alcoholic beverages. Another
! 20% of driver license are shown when people write checks. Another 20%
! fall on miscellaneous identity checks, while in less then 10% of the
! cases a traffic policeman will be the one to see your driver license.
! Clearly, in the U.S. driver licenses are identity cards. In Europe,
! people have government issued identity cards. However, the numbers
! are much less often recorded.
!
! In conclusion, designing a terminology of "identifier types" is
! difficult and has to account for the difference between what an
! identification number is and what it is used for.
!
! Naively one would like to post-coordinate identifier type and
! country/state code, however, as noted above an (SSN, US) is something
! completely different than an (SSN, DE), which means that identifier
! type and country are not really orthogonal. The better approach
! therefore seems to be to assign separate identifier types for each
! type and country of identifier, that is, to pre-coordinate the
! identifier type code. Thus the U.S. SSN would be uniquely identified
! and no other country's SSN would be assigned to the same type. An
! example of a completely pre-coordinated identifier type code is shown
! in the following table.
+
+ Examples of a pre-coordinated terminology of identifier types
+ | code | type | country | state | issuer | notes |
|---|
+ | 001 | SSN | US | | | national person identifier |
+ | 002 | DLN | US | AB | | Alabama |
+ | 003 | DLN | US | AL | | Alaska |
+ | 004 | DLN | US | AZ | | Arizona |
+ | ... | ... | ... | ... | | ... |
+ | 053 | DLN | US | WN | | Wisconsin |
+ | 054 | med. license | US | | AMA | License for U.S. certified Internists. |
+ | 008 | med. license | DE. | BW | LGM | Baden-Württemberg |
+ | 009 | med. license | DE | BA | LGM | Bayern |
+ | 010 | med. license | DE | B | LGM | Berlin |
+ | ... | ... | ... | ... | ... | ... |
+ | 024 | med. license | DE | SWH | LGM | Schleswig-Holstein |
+ | 011 | citizen
+ id | DE | | | the number on the
+ ID card (German "Personalausweis.") |
+ | 012 | citizen id | DK | | | |
+ | 013 | citizen id | FR | | | |
+ | ... | ... | ... | ... | ... | ... |
+ | 123 | patient-id | any | any | any | medical record number, requires issuing auth. |
+ | 124 | inventory | any | any | any | inventory number, requires issuing auth. |
+
+
+ However, there is a downside to pre-coordinated non-hierarchical codes
+ with meaningless identifiers. While these codes comply to the
+ currently touted "good vocabulary practices," the administrative
+ systems that will be using those codes will not be able to make much
+ use from those identifier types. The problem is most obvious when it
+ comes to U.S. driver licenses or German medical licenses. These are
+ issued on a state-level (sub-national governmental agencies.)
+ Therefore, there are 50 codes for U.S. driver licenses and 16 codes
+ for German medical licenses. While this detail is rarely needed, the
+ simple test for "is this a driver license?" is much more difficult
+ than with a simple code "DLN" with the state post-coordinated.
+
+ Those will be the issues that need to be considered when defining
+ the terminology for identifier types. While they are not a core part
+ of this harmonization proposal, they do affect the current information
+ model design and this extended documentation is necessary for the
+ record.
+
+ Definition in the Information Model
+
+ The definition of the Real World Instance Identifier (RWII) is
+ based on a class by the same name in the HL7 Reference Information
+ Model (RIM.) This is so because there is an association between the
+ RWII and an organization as an "assigning athority" of the
+ identifier. This presents a methodological challenge: the RWII should
+ be available as a data type but the data type is associated with an
+ information model class.
+
+ The Unified Modeling Language correctly makes no difference between
+ an attribute's data type and a class, any class can be used as a data
+ type for an attribute. The HL& Modeling and Methodology Committee has
+ decided to accept the notion of a "DMET", that is a Common Message
+ Element Type (CMET) useable in the RIM as a data type. That way we
+ avoid a large bundle of associations connecting from every other class
+ to the RWII class. The following figure shows the new structure of the
+ RIM as of June 1999.
!
!
! 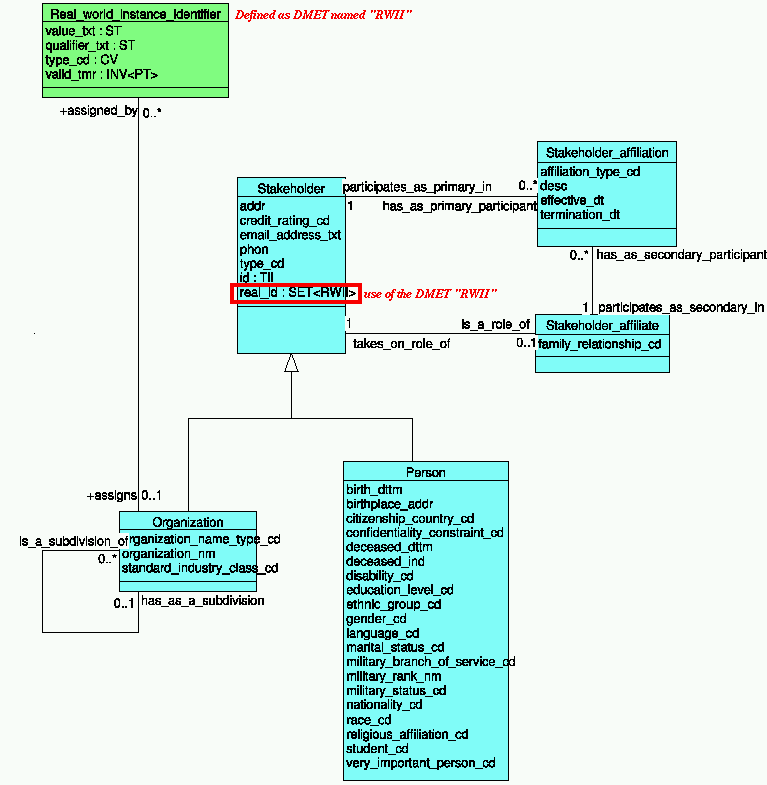 |
! | Figure 5: The
! Real_world_instance_identifier as an information model class. "Users"
! of this class may not associate to it but will refer to the RWII DMET
! as a data type, as shown in the Stakeholder class' "real_id"
! attribute. |
|---|
!
! Definition of the DMET
! The DMET definition of the RWII data type is as follows
!
!
! |
!
! Real World Instance Identifier (RWII) DMET
! |
! |
!
! An identifier for a "real world instance". A real world instance is
! any person, organization, provider, patient, device, animal, or any
! other thing that some organization recognizes and assigns an
! identifier to. Examples are Social Security Number, Driver License
! Number, Inventory Number, HCFA Provider ID, Medical Record Number.
! Typically, real world instance identifiers are assigned and reused
! outside of HL7 communication. These identifiers tend to be less
! reliable than Technical Instance Identifiers that are assigned and
! maintained exclusively by HL7 communication systems. Other classes
! use this class not by associations but by declaring attributes of type
! "RWII."
! |
!
! | component name |
! type/domain |
! optionality |
! description |
!
! | value_txt |
! Character String |
! mandatory |
!
! The character string value of the identifier. For example the
! character string "123-45-6789" for a U.S. Social Security Number."
! |
! | type_cd |
! Code Value |
! mandatory |
!
! A code representing the type of identifier. For example, codes to
! represent the US National Provider ID, US National Payor ID, US Health
! Care ID, medical record number, social security number.
! |
! | qualifier_txt |
! Character String |
! conditional |
!
! Information used to limit the applicability of a real world instance
! identifier, such as the state or province in which the identifier is
! valid. Use and interpretation depends on the type_cd.
! |
! | valid_tmr |
! Interval of Point
! in Time |
! optional |
!
! The time range in which the identifier is valid. May be undefined on
! either side (effective or expiration).
! |
! | assigned_by |
! Organization (RIM class CMET) |
! conditional |
!
! The assigning authority of the identifier if not implicit in the
! type_cd. The Organization CMET used here is likely to be very
! terse.
! |
! While the value_txt is always a mandatory part of a real world
! identifier, the qualifier_txt must, may, or must not be valued
! depending on the identifier type_cd. This is independent of whether a
! precoordinated or a postcoordinated identifier type coding scheme is
! used. As the above table suggests, there is no way to completely
! precoordinate identifier type codes when the issuer organizations are
! not "well known" (e.g., providers, insurers.)
!
! For example, the state of the U.S. driver license is either
! precoordinated in the identifier type_cd or it is post-coordinated in
! the qualifier_txt. The qualifier_txt can be used for patient
! identifiers to allow issuing authorities to maintain multiple
! namespaces (e.g., for multiple clinical trials.)
!
! The actual use of the real world instance identifier should not be
! coded in the type_cd but should be given implicitly through
! establishing many more attributes in a many classes that have the data
! type RWII (a DMET.) For example, rather than pushing all stakeholder
! identifiers up to the highest level, the Stakeholder class should have
! an identifier only for such identifiers as SSN, EIN, ITIN, passport
! number, person id. Medical record numbers (patient id) should be
! declared as an attribute of the Patient class. Provider license
! numbers should be declared in the Individual_health_care_provider
! class, etc.
!
! The identifier issuing authority is a conditional component of the
! real world instance identifier. The organization will not be
! mentioned in a message for "well known" issuers (e.g., SSN, DLN, etc.)
! The organization will be mentioned by a brief object stub for in-house
! communication. For third-party organizations and for inter-enterprise
! communication, there will be more information given for the issuing
! organization.
!
! Finally, it must be noted that technical instance identifiers (TII)
! are a much more economic structure to identify patients and things in
! HL7 messages for routine use. After external identifiers (RWIIs) have
! been exchanged once, follow-up messages should generally suffice with
! TIIs.
!
! Medical Record Numbers (MRN) as used in the world of
! Paper Medical Records are another example for such real world instance
! identifiers. Note that in the computer world, we would not need MRNs,
! since we could use Technical Instance
! Identifiers (TII) to refer to computerized medical
! records. However, Wes Rishel and I think that as a rule of thumb, TIIs
! should not be communicated through human middlemen in order to keep
! reliability in their correctness high. Thus, as long as MRNs are typed
! in by clerks and other people, one should separate them from TIIs.
!
***************
*** 5755,5761 ****
|
! Postal and Residential Address
|
|---|
--- 6143,6149 ----
|
! Postal and Residential Address (AD)
|
|---|
***************
*** 5815,5821 ****
|
! Address Part
|
|---|
--- 6203,6209 ----
|
! Address Part (ADXP)
|
|---|
|
***************
*** 6270,6276 ****
Word.
! Hopkins R. Strategic short study: names and numbers as
identifiers. CEN TC251. Available as
PDF or
Word.
--- 6658,6664 ----
Word.
! Hopkins R. Strategic short study: names and numbers as
identifiers. CEN TC251. Available as
PDF or
Word.
***************
*** 6294,6312 ****
Data Type Specification for Person Name
! Earlier discussions included class person name and person name
! variant, but we found the requirement to model person name as a RIM
! class. What we did not realize is that, similar to the stakeholder id,
! our RIM class already exists, it only needs to be polished.
!
! The RIM class Person_name will be developed from the class
! Person_alternate_name of RIM 0.88 jointly with PAFM. A person may have
! multiple instance of the person name class, reflecting the multiple
! names the person is or was known by.
!
! Within this RIM class, there is a code that indicates what purpose
! a given name is to be used for. Most people in the world will have one
! name that is currently used.
Name Purpose Codes
--- 6682,6700 ----
Data Type Specification for Person Name
! The Person_name is a RIM class as of June 1999. This class is
! correctly associated with the class Person and the multiplicities of
! this association allow one person to have multiple names. A second
! association ("is_used_by") to the class Statkeholder allows a person
! name to be scoped to some organization (or even another individual
! person.)
!
! Within this RIM class Person_name, there is an attribute that
! indicates what purpose a given name is to be used for ("reason_cd")
! Most people in the world will have one name that is currently
! used. The following table is the Control Query recommendation to PAFM
! for a mandatory vocabulary for Person_name.reason_cd. We also suggest
! to rename this attribute to "purpose_cd".
Name Purpose Codes
***************
*** 6332,6350 ****
! Note that name purpose codes apply to an entire name that usually
consists of several of the name parts described below.
There is also a way to specify the validity time of a name.
! This class also contains a representation of a single name variant
! as a list of person name parts that may or may not have semantic tags.
!
! Those RIM changes will have to be discussed jointly with CQ and
! PAFM at the Toronto meeting in April 1999. We will seek definite
! closure on the issue in Toronto after which Harmonization will be but
! a formal issue, since all relevant parties will have agreed to one
! proposal.
--- 6720,6733 ----
! Note that name purpose codes apply to an entire name that usually
consists of several of the name parts described below.
There is also a way to specify the validity time of a name.
! This class also contains an attribute "nm" which contains a single
! name variant as a list of person name parts that may or may not have
! semantic tags. This person name data type (PN) is defined as follows:
***************
*** 6372,6378 ****
|
! Person Name Part
|
|---|
--- 6755,6761 ----
|
! Person Name Part (PNXP)
|
|---|
|
***************
*** 6405,6410 ****
--- 6788,6801 ----
|
+ Note that the Person Name (PN) data type is different from the
+ Person_name class. The data type is not a CMET or DMET of the class
+ but is used by the class as the data type of one of its
+ attributes. The naming overlap is to indicate that this HL7 version 3
+ PN data type is the successor of the HL7 version 2 PN data type, while
+ the Person_name class can be understood as the successor of the
+ version 2 XPN data type.
+
Name Part Classifiers
***************
*** 6507,6513 ****
| invisible | 0 (zero) | Indicates that a
name part is not normally shown. For instance, traditional maiden
! names are not normally shown. Middle names may be invisible too. |
| weak | W | Used only for
prefixes and suffixes (affixes). A weak affix has a weaker association
--- 6898,6913 ----
| | invisible | 0 (zero) | Indicates that a
name part is not normally shown. For instance, traditional maiden
! names are not normally shown. "Middle names" may be invisible too. |
!
! | middle | MIN | Emphasizes that
! a name part is "the middle name" in the classic U.S. American
! First-Middle-Last name scheme. This classifier may only appear once in
! the entire name and may only be ascribed to the second given
! name part. No other use is permitted. Note that this tag is optional
! and completely redundant since the second of two given names can
! always be assumed to be "the middle name". It has been adopted only
! to satisfy public demand. |
| weak | W | Used only for
prefixes and suffixes (affixes). A weak affix has a weaker association
***************
*** 6673,6679 ****
the data type definition. Not that nesting is a bad idea per
se. However, since the nesting depth appears to be limited to
three levels, the generality of nesting seems to not outweigh the
! wimplicity of a simple linear list.
There are other ramifications though, such as prefixes that consist
of more than one part such as in French "Eduard de l'Aigle". Here "de
--- 7073,7079 ----
the data type definition. Not that nesting is a bad idea per
se. However, since the nesting depth appears to be limited to
three levels, the generality of nesting seems to not outweigh the
! simplicity of a simple linear list.
There are other ramifications though, such as prefixes that consist
of more than one part such as in French "Eduard de l'Aigle". Here "de
***************
*** 6878,6905 ****
distinct name forms that we decided to threat as separate Person names
without trying to relate those name parts accross the variants.
- The following is the first example of a complete Person Name
- structure.
-
Bob Dolin, Robert Dolin, or Robert H. Dolin
! (SET
! (Person_name
! :value (PN
(PersonNamePart :value "Bob"
:classifiers (SET given nick))
(PersonNamePart :value "Dolin"
:classifiers (SET family))))
! (Person_name
! :value (PN
(PersonNamePart :value "Robert"
:classifiers (SET given))
(PersonNamePart :value "Dolin"
:classifiers (SET family))))
! (Person_name
! :value (PN
(PersonNamePart :value "Robert"
:classifiers (SET given))
(PersonNamePart :value "H."
--- 7278,7300 ----
distinct name forms that we decided to threat as separate Person names
without trying to relate those name parts accross the variants.
Bob Dolin, Robert Dolin, or Robert H. Dolin
! (PN
(PersonNamePart :value "Bob"
:classifiers (SET given nick))
(PersonNamePart :value "Dolin"
:classifiers (SET family))))
!
! (PN
(PersonNamePart :value "Robert"
:classifiers (SET given))
(PersonNamePart :value "Dolin"
:classifiers (SET family))))
!
! (PN
(PersonNamePart :value "Robert"
:classifiers (SET given))
(PersonNamePart :value "H."
***************
*** 6908,6913 ****
--- 7303,7309 ----
:classifiers (SET family)))))
+
we did not classify the person name variants here, since this would
open up another can of worms. It almost seems like there is a gradual
scale of formality which tells which of the various person names to
***************
*** 7349,7355 ****
or "deed poll". There is considerable overlap with the
unmarried name classifier and the other classifiers of Axis 2.
Consequently we had to relax the notion that axis 2 classifiers need
! to be mutual exclusive.
Initials
--- 7745,7751 ----
or "deed poll". There is considerable overlap with the
unmarried name classifier and the other classifiers of Axis 2.
Consequently we had to relax the notion that axis 2 classifiers need
! to be mutually exclusive.
Initials
***************
*** 7426,7461 ****
unless there is any significant objection we can just stick to a
v2.3-like solution.
!
!
!
!
!
!
|
! Organization Name Variant
|
|---|
|
! This type is not used outside of the Organization Name data type. Organization
! Names are regarded as a collection of organization name variants each
! used in different contexts or for a different purpose.
|
| component name |
--- 7822,7837 ----
unless there is any significant objection we can just stick to a
v2.3-like solution.
!
|
! Organization Name Variant (ON)
|
|---|
|
! A name for an organization. (What else is there to say?)
|
| component name |
***************
*** 7467,7473 ****
Code Value |
optional |
! A type code indicates what an organization name is to be used
for. Examples are: alias, legal, stock-exchange.
|
| value |
--- 7843,7849 ----
Code Value |
optional |
! A code indicating what an organization name is to be used
for. Examples are: alias, legal, stock-exchange.
|
| value |
***************
*** 7476,7492 ****
mandatory |
! This contains the actual name data as a simple character string.
|
!
!
!
!
--- 7852,7881 ----
mandatory |
! The actual name data as a simple character string.
|
+ Note: this has changed. In a previous draft the
+ Organization Name (ON) was a set of Organization Name Variants
+ (ONXV) with no additional information. It is therefore simpler to
+ define ON in parallel with PN as representing one name variant and let
+ PAFM handle the rest in the RIM.
+ Note: a harmonization request to PAFM is required
+ for the Organization class to
+
+ delete attribute: Organization.organization_name_type_cd
+ Rationale: Attribute duplicates the ON.type component of the
+ Organization name data type.
+
+ rename attribute: Organization.organization_nm to "nm"
+ Rationale: Name does not conform to the MDF style guide as it
+ repeats the name of its class.
! assign data type: Organization.nm : SET<ON>
!
***************
*** 7525,7555 ****
can not be considered exact.
Most computer programming languages distingush between the two data
! types integer and floating point number. Some know rationals and
! complex numbers. Whereas HL7 v2.x had only one data type for numbers,
! HL7 v3 will distinguish between interger and floating point. This
distinction is suggested not just by technological considerations
! (both are implemented quite differently).
! The main reason for distinguishing integer and floating point
! numbers is about semantics. Integer numbers are exact results of
! counting and enumerating. In natural science and real life, integer
! numbers are rather rare. Measurements, estimations, and many
! scientific computations have floating point numbers as their results,
! imprecise real numbers. Measurements are but approximations to the
! quantitative phenomena of nature.
There are other distingished quantitative phenomena that can be
partially described by numbers but which have a meaning beyond
numbers. Among such quantitative phenomena are physical measurements
with units of measure, money, and real time as measured by clendars.
! This specification defines data types for integer and floating
! point numbers, for physical measurements, money, and calendars. There
! are many more quantitative phenomena that we may or may not define
! data types for in the future. Examples for those we will define are
! vectors, waveforms, and possibly matrices. We will probably not
! consider complex numbers, except if a concrete use case appears.
4.2 Integer Number
--- 7914,7944 ----
can not be considered exact.
Most computer programming languages distingush between the two data
! types integer and real (floating point) number. Some know rationals
! and complex numbers. Whereas HL7 v2.x had only one data type for
! numbers, HL7 v3 will distinguish between interger and real. This
distinction is suggested not just by technological considerations
! (both are implemented quite differently).
! The main reason for distinguishing integer and real numbers is
! about semantics. Integer numbers are exact results of counting and
! enumerating. In natural science and real life, integer numbers are
! rather rare. Measurements, estimations, and many scientific
! computations have real numbers as their results, imprecise real
! numbers. Measurements are but approximations to the quantitative
! phenomena of nature.
There are other distingished quantitative phenomena that can be
partially described by numbers but which have a meaning beyond
numbers. Among such quantitative phenomena are physical measurements
with units of measure, money, and real time as measured by clendars.
! This specification defines data types for integer and real numbers,
! for physical measurements, money, and calendars. There are many more
! quantitative phenomena that we may or may not define data types for in
! the future. Examples for those we will define are vectors, waveforms,
! and possibly matrices. We will probably not consider complex numbers,
! except if a concrete use case appears.
4.2 Integer Number
***************
*** 7557,7563 ****
|
! Integer Number (Integer, IN)
|
|---|
--- 7946,7952 ----
|
! Integer Number (INT)
|
|---|
***************
*** 7617,7635 ****
! 4.3 Floating Point Number
|
! Floating Point Number (Float, FPN)
|
|---|
|
! Floating point numbers are approximations for real numbers. Floating
! point numbers occur whenever quantities of the real world are measured
or estimated or as the result of calculations that include other
! floating point numbers.
|
| component name |
--- 8006,8031 ----
!
! 4.3 Real Number (was: Floating Point Number)
!
! Note: can we change the name in the
! last minute? I realized too late that calling it "Floating Point
! Number" is incorrect, since that name refers to a particular
! computer-representation of a number. I would now much rather call it
! "Real".
|
! Real Number (was: Floating Point Number, FPN)
|
|---|
|
! A data type that approximates real numbers to a certain precision.
! Real numbers occur whenever quantities of the real world are measured
or estimated or as the result of calculations that include other
! real numbers.
|
| component name |
***************
*** 7649,7672 ****
Integer Number |
required |
! The precision of the floating point number in terms of the number of
significant decimal digits.
|
Semantic components vs. representational components
! A floating point number has the semantic components value
! and precision, however, this does not necessarily mean
! that any representation of a floating point number will be a structure
! of two distinct components. Especially, since we do not specify a data
! type for true real numbers of infinite precision, the
value component is not of an existing data type.
Precision
! The precision of a floating point number is defined here as the number
of decimal digits. According to Robert S. Ledley [Use of
computers in biology and medicine, New-York, 1965,
p. 519ff]: "A number composed of n significant figures is
--- 8045,8074 ----
Integer Number |
required |
! The precision of the real number in terms of the number of
significant decimal digits.
|
Semantic components vs. representational components
! A real number has the semantic components value and
! precision, however, this does not necessarily mean that
! any representation of a floating point number will be a structure of
! two distinct components. Especially, since it is not possible to
! define a data type for true real numbers of infinite precision, the
value component is not of an existing data type.
+ Rather than being components of the data type "value" and
+ "precision" that can be evaluated on the application layer. These
+ properties must be kept invariant throughout all ITS
+ implementations. This is especially an issue if binary floating point
+ numbers are used, such as IEEE 754.
+
Precision
! The precision of a real number is defined here as the number
of decimal digits. According to Robert S. Ledley [Use of
computers in biology and medicine, New-York, 1965,
p. 519ff]: "A number composed of n significant figures is
***************
*** 7723,7732 ****
are well known in the medical profession. However, these statistical
methods are quite complex, and exact probability distributions are
often unknown. Therefore, we want to keep those separate from a basic
! data type of floating point numbers. However, floating point numbers
! are approximations to real numbers and we want to account for this
! approximative nature by keeping a basic notion of precision in terms
! of significant digits right in the floating point data type.
In many situations, significant digits are a sufficient estimate of
the uncertainty, but even more important, we must account for
--- 8125,8134 ----
are well known in the medical profession. However, these statistical
methods are quite complex, and exact probability distributions are
often unknown. Therefore, we want to keep those separate from a basic
! data type of real numbers. However, a data type for real numbers can
! only be an approximation to true real numbers and we want to account
! for this approximative nature by keeping a basic notion of precision
! in terms of significant digits right in the real number data type.
In many situations, significant digits are a sufficient estimate of
the uncertainty, but even more important, we must account for
***************
*** 7738,7766 ****
No fixed arbitrary limits on value range
! No arbitrary limit is imposed on the range or precision of floating
! point numbers. Thus, theoretically, the capacity of any binary
representation is exceeded, whether 32 bit, 64 bit, or 128 bit
size. Domain committees should not limit the ranges and precision of
! floating point numbers only to make sure the numbers fit into current
! data base technology. Designers of Implementable Technology
! Specifications (ITS) should be aware of the possible capacity limits
! of their target technology.
!
! The infinity of floating point numbers is represented as a special
! value. The representation of floating point numbers is up to the
! ITS. In our instance notation we use the special symbol
! #finf for positive infinity (Aleph1),
! #nfinf for negative infinity (-
! Aleph1.) Note that #nfinf = -
! #finf.
Constraints on value ranges
In cases where limits on the value range are suggested semantically
by the application domain, the committees should specify those
! limits. For example, probabilities should be expressed in floating
! point numbers between 0 and 1.
Although we do not yet have a formalism to express constraints, we
should not hesitate to document those constraints informally. We will
--- 8140,8167 ----
No fixed arbitrary limits on value range
! No arbitrary limit is imposed on the range or precision of real
! numbers. Thus, theoretically, the capacity of any binary
representation is exceeded, whether 32 bit, 64 bit, or 128 bit
size. Domain committees should not limit the ranges and precision of
! real numbers only to make sure the numbers fit into current data base
! technology. Designers of Implementable Technology Specifications (ITS)
! should be aware of the possible capacity limits of their target
! technology.
!
! The infinity of real numbers is represented as a special value. The
! representation of real numbers is up to the ITS. In our instance
! notation we use the special symbol #finf for positive
! infinity (Aleph1), #nfinf for negative
! infinity (- Aleph1.) Note that #nfinf
! = - #finf.
Constraints on value ranges
In cases where limits on the value range are suggested semantically
by the application domain, the committees should specify those
! limits. For example, probabilities should be expressed in real numbers
! between 0 and 1.
Although we do not yet have a formalism to express constraints, we
should not hesitate to document those constraints informally. We will
***************
*** 7769,7791 ****
ITS Presentation and Literals
! We allow floating point numbers to be represented by character
! string literals containing signs, decimal digits, a decimal point and
exponents. An ITS for XML will most likely use the string literal to
! represent floating point numbers. Other ITSs, such as for CORBA, might
! choose to represent floating point numbers by variable length bit
! strings or by choices of either a native (IEEE) floating point format
! or a special long floating point format.
!
! Decimal floating point numbers can be represented in a standard
! way, so that only significant digits appear. This standard
! representation always starts with an optional minus sign and the
! decimal point, followed by all significant digits of the mantissa
! followed by the exponent. Thus 123000 is represented as
! ".123e6" to mean .123 × 106; 0.000123 is
! represented as ".123e-3" to mean .123 ×
! 10-3; and -12.3 is represented as "-.123e2".
! to mean -.123 × 102.
The reason why we define decimal literals for data types is to make
the data human readable. To render the value 12.3 as
--- 8170,8191 ----
ITS Presentation and Literals
! We allow real numbers to be represented by character string
! literals containing signs, decimal digits, a decimal point and
exponents. An ITS for XML will most likely use the string literal to
! represent real numbers. Other ITSs, such as for CORBA, might choose to
! represent real numbers by variable length bit strings or by choices of
! either a native (IEEE 754) floating point format or a special long
! floating point format.
!
! Decimal real numbers can be represented in a standard way, so that
! only significant digits appear. This standard representation always
! starts with an optional minus sign and the decimal point, followed by
! all significant digits of the mantissa followed by the exponent. Thus
! 123000 is represented as ".123e6" to mean .123 ×
! 106; 0.000123 is represented as ".123e-3" to
! mean .123 × 10-3; and -12.3 is represented as
! "-.123e2". to mean -.123 × 102.
The reason why we define decimal literals for data types is to make
the data human readable. To render the value 12.3 as
***************
*** 7833,7839 ****
| ::= |
sign digits | digits |
! | float |
::= |
mantissa e exponent |
mantissa |
--- 8233,8239 ----
::= |
sign digits | digits |
! | real |
::= |
mantissa e exponent |
mantissa |
***************
*** 7900,7906 ****
defines a generalization of rational numbers, the Ratio. A ratio is
any quotient of two quantities. Those can be two integers, in which
case we have an exact rational number. But the quotient can be built
! as well from floating point values, or physical measurements or any
combination thereof.
Note that the ratio has the semantics of a quotient. The ratio data
--- 8300,8306 ----
defines a generalization of rational numbers, the Ratio. A ratio is
any quotient of two quantities. Those can be two integers, in which
case we have an exact rational number. But the quotient can be built
! as well from real number values, or physical measurements or any
combination thereof.
Note that the ratio has the semantics of a quotient. The ratio data
***************
*** 7911,7917 ****
|
! Ratio
|
|---|
--- 8311,8317 ----
|
! Ratio (RTO)
|
|---|
|
***************
*** 7943,7949 ****
A Quantity is a generalization of the following data types:
| | | | | | | | | | | | | | | | | | | | | |
 !
! 
 ) and intersection (
) and intersection ( ) to form the complex
! specification of business hours shown in the introductory example:
!
) to form the complex
! specification of business hours shown in the introductory example:
!