The HL7 version 3 data type task group has had its fourth conference call on Thursday, October 29, 1998, 11 to 12:30 AM EDT.
Attendees were:
Writing minutes and running through a conference becomes rather
simple with the preparation of a
worksheet :-)
We made it through worksheet item 1.1 and 1.2 and we did some initial
negotiations on 2.1--2.4. More details about the rationale of these
proposed data types can be found in the
notes of the last call.
| Unravelable Technical Instance Identifier | |||
|---|---|---|---|
| This data type is used to uniquely identifiy some entity that exists within some computer system. Examples are object identifier for RIM class instances, things like medical record number, placer and filler order number, service catalog item number, etc. | |||
| component name | type/domain | optionality | description |
| root |
ISO Object Identifier |
required | This is the required field that guarrantees the uniqueness of the identifier and that permits the origin of the identifier to be determined (un-raveled). This can be the only field in institutions that use OIDs for their internal object identifiers. |
| extension | Charater String | optional | The extension can be used in case an institution uses non-OID identifiers locally and does not want to map every internal identifier to OIDs. Especially useful if the local identifiers are not purely numeric. This field may never ever be send alone without the connecting root OID. |
Larry Reis, while not objecting against the approach, was concerned about vendor acceptance. Mark Shafarman expressed similar concerns. The concerns can be divided into two categories:
|
| Figure 1: The the hierarchy of ISO Object Identifiers and how it could be used by HL7. |
|---|
ISO Object Identifiers come with the blessing of being world-wide unique and endorsed by the International Organization for Standardization (ISO). At the downside, one might be afraid how difficult it will be for small vendors and users to make all the bureaucrates happy just in order to get one of such a unique Object Identifier.
The good news is that no HL7 vendor or user has to contact ISO in order to get an OID. OIDs are assigned hirarchically so that every OID can itself be reused as the basis for a large tree of other OIDs. As soon as you have one OID you are an assigning authority by yourself. No need for you to contact anyone else in order to issue other OIDs.
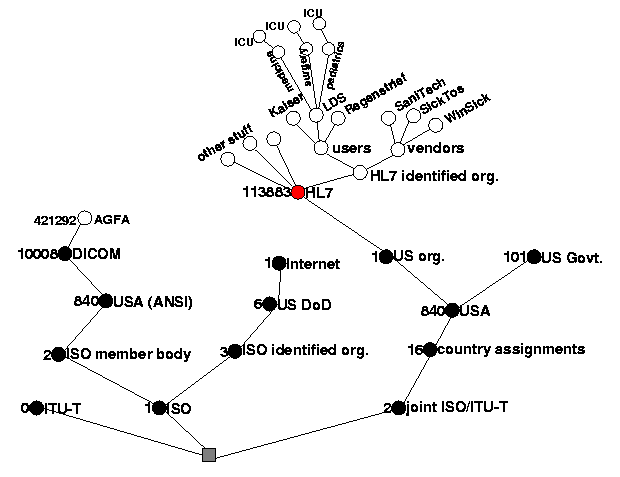
HL7 itself has ackquired an OID recently. This makes HL7 an assigning authority. On the one hand, we may use OIDs for HL7 internal things. On the other hand we could have one branch for HL7 identified organizations. This branch could be subdivided into users and vendors.
A vendor who has ackquired an OID could name all his HL7 related products machines, software, single installations of their software and so on as OIDs in their subtree.
The Letter Day Saints (LDS) Hospital in Salt Lake City would have an OID at the user's side. They can, for example, subdivide their tree in pediatrics/medical/surgical departments where each of them may have an ICU subdepartment with its systems and subsystems and so on. The Idea is that everyone can do with its part of the subtree whatever they want. Regenstrief and Kaiser would have their OIDs to organize their namespace as they see fit.
The point is that you need to get your foot into the door only once. Once you have your OID, you do with it whatever you want. It's just like you can design your directory hierarchy on your hard disk just as you want. You can stick toi a convention, you can do chaos, as you see fit.
The only outstanding issue in ackquiring OIDs is how HL7 is going to manage this. Management of OID assignment is fairly simple. DICOM does it and IANA (Internet) does it for free. So it can't bee too difficult. What is needed is just one data base where you map OIDs between organizations, vendors or users, and keep some contact address on file. This can be automatized, with a Web-based application form.
Anyway, we may want to ask our DICOM and ANSI collegues to learn about their experience in the OID assignment business.
1.2.840.12345.4.1.123456.32.101.12345.54321
That's 44 characters. DICOM has set the maximal length to about 60 or
80 characters. I don't think that we should set any particular maximal
length, since that would bring us into trouble sometime in the
future. However, reasonably those numbers rarely exceed 60 to 80
characters.
But there is even a way to get around with only 8 characters. Here is how:
No one should have trouble sending or receiving those long OIDs. The problem with length is only about storing OIDs in data bases. Now you can use an OID data base at your system that can handle long OIDs and maps those to 8 byte base 64 strings. This allows you to store a total of 648 = 281474976710656 different identifiers. This is 2.814 x 1015, a thousand-trillion numbers. Suppose you would waste those identifiers at a rate of 1000 per second, your namespace would still not overflow in 8900 years! We can safely assume that by that time, an 80 character OID would no longer be a problem, would it?
Stan Huff raised the concern that it is difficult to interpret OIDs in a globally agreed way. The Andower Working Group obviously tried to design the OID namespace structure in a way that OIDs would not only identify instances but would also classify them.
So the question is: can we parse an OID and get any information from it? Can we learn anything about an instance just by looking at its OID? Things that we might what to find in an OID are: What Application? What Facility? What Department? What Country? What Location? Which Type? etc.
Here we should come back to review our goal: we wanted to design an unique identifier for technical instances. Uniqueness that comes through hierarchical structure of the namespace brings with it the quality of un-ravelability of identifiers. But the original meaning of "un-ravelable," as coined by Mark Tucker, was that unraveling an identifier is a painful and slow process. You use the phone, calling up ISO, ANSI, HL7, LDS, and so on until you have someone on the phone who is responsible for that number. Unraveling is nothing that a computer could do for you automatically. (That would be dereferencing or resolving an identifier.)
So, in general, we concluded, and Stan Huff himself suggested that option, we would deny that one could infer any meaning from the OID alone.
However, we would not forbid owners of OIDs to "design" their subtree in some meaningful way. For instance, Intermountain Healthcare could assign an OID to each of its institutions, the next level would contain departments. In each departments the number 1 would be the administrative section, number 2 would be the ICU, number 3 would be the lab, number 100 to 999 would be the normal inpatient wards, and so on.
Everyone would be free to design and use his own OID structure to make decisions. However, no one outside would be forced to do the same structuring. Thus, Intermountain Healthcare could base it's message routing heavily on the structures of their OIDs, but as soon as they receive something from the Utah State Dept. of Health or from the CDC, they would not necessarily be able to infer any meaning from the OIDs assigned by those other organizations.
This really asks whether we can reduce the size of messages by setting any specific context, probably in the message header, which would be attached at the front of each incomplete OID that appears in the message.
Apart from reducing message length, this does not seem to be a particulary useful feature. ISO Object Identifiers do not support any left-side incompleteness. We probably need not bother.
What we should be very careful about is to losen up the rigor of the HL7 spec. The root OID is required in the data type for "unravelable technical instance identifiers." If anyone absolutely believes to be unable to comply with this demand, it should certainly be clear that we do not endorse this (although HL7 has, of cource, no data-type-police who enforces the spec.)
In the end we have to find nice words to sell this data type. I guess, its main benifits, as it stands, are:
As it stands, we do not allow different identifier schemes. For good reasons we do not allow Internet domain names as unique identifier schemes. Not because the Internet is bad, but because domain names can change. Domain names are designed for flexibility and live in the present. The DNS is not designed for longevity.
But what about the Unique/Universal Identifiers (UID) used by the Open Software Foundation's (OSF) Distributed Computing Environment (DCE)? What about the identifiers used by CORBA?
We did not have the expertise on this conference to really know what we are ruling out when we decide for only ISO OIDs. All participants are requested to find out about the other identifier schemes. Specifically Randy Marbach will ask his colleques about DCE's UIDs.
Joann Larson whats to contribute examples of those identifiers.
No one objected against this data type as proposed. This means silent agreement. (is there any convention on how one could vote on a phone conference?)
ISO-OSI/ASN.1 Object Identifiers are a special data type of the form SEQUENCE OF CARDINAL. However, DICOM uses OIDs as character strings containing only numbers and dots. Mark and I prefer the DICOM way of doing OIDs, because it is just easier.
We might want to have a printname for OIDs too. This printname would, again, be sent as a curtesy, not having any meaning on its own. ISO has a special style of writing cleartext OIDs of the form:
ISO (1).ISO-member-body (2).USA (840).HL7
(12345).HL7-identified-organization (4).users
(1).Intermountain-Healthcare (123456).pediatrics (32).ICU
(2).monitor-infosys (12345).54321
We could say that an OID literal can appear in either form, with or
without full names. Just like you can write an e-mail address in two
forms "zxmsd01@domain.iupui.edu" and "Charlie
Chaplin <zxmsd01@domain.iupui.edu>" (foolish who says
"zxmsd01@136.68.45.123" although that can be done too!)
However, the reason why we do not want to do this is because we want to be able to compare OIDs just literally, without having to parse them. A canonical representation is needed to do this. The canonical representation would allow only digits and dots, where the zero may not occur in a leading position, except if it is directly followed by a dot.
| Dereferenceable Technical Instance Identifier | |||
|---|---|---|---|
| This is a dereferencable locator for some instance. For example, a bunch of radiology images that can be retrieved on demand. A given instance of this data type may not be valid forever. | |||
| component name | type/domain | optionality | description |
| protocol |
Code Value for technical concepts |
required | This mentions the protocol that can interpret the access string and can do something useful for the user to render the patrticular technical instance refered to. This may be spawning a WWW browser with a particular URL, fetching a DICOM image and show it, or opening a telephone connection to another party. |
| address | Charater String | required | This is an arbitrary address string that must be meaningful to the protocol. |
This data type is basically the URL. However. URLs are not maintained by HL7 and we want to have more freedom on definig our own protocols without adjustment to IETF needs.
An example is telephone numbers.
Examples for this type are:
This needs more specification, i.e. how URL's are constructed from that type. Who wants to take on that job?
Note that we renamed this data type from "identifier" to "locator". (Note also that these are deliberately long names that need not be the final names we might choose for our data types. The names are long for clarity, to avoid confusion with premature acronymes.)
This type was not controversial.
We will still define as successor of the reference pointer (RP) to include more information about the thing that is refered in this locator.
This outer data type would also contain sort of an expiry date.
We didn't have enough time to discuss this in detail. It will be the first topic to address our next call. Some issues and comments are dropped in below as they came up.
The data type for Real World Concepts will be defined in as follows.
This is a bottom up approach! I defined the small data types before the bigger ones.
This means, not every of those types is actually used by those who define messages. We will probably only use the "Code Value" and the "Concept Descriptor" as top-level data types. The rest is just names for the nested structures within the "Concept Descriptor".
See also the the prior version of this proposed type and its notes and comments: [version 1]. Note that this proposed data type has been updated: [version 3]
| Code Value | |||
|---|---|---|---|
| A code value is exactly one symbol in a code system. The meaning of the symbol is defined exclusively and completely by the code system that the symbol is from. | component name | type/domain | optionality | description |
| value | Character String | required |
this is the plain symbol, like "784.0"
|
| code system | a code by itself | required, can be fixed by context |
denotes the code system that defined the plain symbol |
| code system version | Character String | optional | a version descriptor defined specifically for the given code system. |
| print name | Character String | optional | a sensible name for the code as a curtesy to an interpreter of the message. THE PRINTNAME HAS NO MEANING, it can never be sent alone and it can never modify the meaning of the code value |
This one is not controversial.
We might attach the meaningless printname for what Stan calls "exception handling" (more about that below).
Note that this proposed data type has been defined again without changes, but check out further notes and comments there: [version 2].
| Code Phrase | |||
|---|---|---|---|
| A code phrase is a list of code values which all together make up a meaning. This can be used for example in SNOMED, where you can combine multiple codes into a new composite meaning. HL7 used to combine codes and modifiers for the OBR specimen source. And HCFA procedure codes also come with modifiers. | |||
| ORDERED LIST OF Code Value |
This has been renamed from "Code Term" to "Code Phrase." I wanted to do this in the first place but forgot. Mark Tucker brought that idea back to my mind!
"Code Phrase" expresses better what I intended to do here. A code phrase in a multi-axial postcoordinated code system (such as SNOMED) may be translated to a single code value in a single-axial precoordinated code system (such as LOINC).
This is the reason why modifiers exist on the intermediate level and not on the highest level.
For me, code modifiers are dependent on the coding system used. Thus we can not take one concept descriptor with a bunch of synonyms and modify this with another concept descriptor. If code modifiers are needed, they should apply before any translation into another code.
Note that this proposed data type has been defined again without changes, but check out further notes and comments there: [version 2].
| Code Translation | |||
|---|---|---|---|
| This data type holds one code phrase as one translation in a set of translations describing a concept. The additional information in this data type points to the source code used in the translation process and describes who or what performed the translation and what the quality of this translation is. | |||
| component name | type/domain | optionality | description |
| term | Code Phrase | required | All the meaning of the translation is found here, the rest is descriptive stuff. |
| origin |
reference to CodeTranslation |
required | This is the code in the list of translations on which this translation was based. This is a required component which means, whoever adds an additional translation must reference the source code. No reference here means that the given translation is the original code. |
| producer |
Unravelable Instance Identifier |
optional | This identifier tells what system performed the translation. This information can be useful to audit the translation process or to estimate the quality of the coding based on prior experience with a the translation of a given producer. This identifier refers to some system not a particular human coding clerk. However, the system identifier can be fine grained enough so that the human operator can be determined in the process of unraveling the identifier. |
| quality |
Floating Point Number [0..1] |
optional | An estimation of the translation quality. This is a value between 0 and 1, where 1 stands for an absolutely accurate translation and 0 stands for random fuzz. We do not require a special method to be used here to estimate the quality. This can just be a subjective estimation of the form we use in eliciting probablilities for a belief network. But we can recommend some example methods of how those values can be computed. We can also map all other quality estimations mentioned in the literature onto the interval [0..1] of real numbers. |
Examples, we need examples!!! (see below).
Note that this proposed data type has been defined again without changes (dependent data types may have changed though). Check out further notes and comments there: [version 2].
| Concept Descriptor | |||
|---|---|---|---|
| A concept descriptor communicates a real world concept (such as a finding or a diagnosis). A given concept may be expressed in multiple terms where each term is a translation of some other term, or is a (re-)encoding of the original human readable text. | |||
| component name | type/domain | optionality | description |
| translations |
SET OF Code Translations |
required | These are the translations or quasi-synonyms of one real world concept. Every translation in the set is supposed to "say the same thing in different words." The translations in the set form one directed graph that is fully connected. |
| original text | Free Text | optional | This is the original text or text-phrase entered by a clinician that was the basis for the initial coding. This can also be the text that was displayed to the clinician in a selection menu and thus was the basis for the selection of the particular initial code term in the set of translations. |
Examples: A code value for the hair color "ash-blond" in some local hair color code:
Suppose, the CDC is conducting a study to corelate ear infection with hair color. The Pilological Society of America (PILS-A) just has agreed on an Advanced Hair Color Code (AVACC), which CDC is using for its study. This code is post-coordinated. It has the axes (1) base color (black, brown, blond) (2) gray-tone (none, slight, medium, strong) and (3) homogeneity (homogene, spotty, ... [here I could be more creative in my native language]). The translator guesses that "blond, slight, homogene" would fit best (although the original text didn't say anything about homogeneity). So we add that other translation:
I did not show the features quality and producer of a translation here.
Stan Huff's main concern here was about "exception handling." An exception in this system of coding and translating occurs if some particular quality that was observed can not be coded.
For example, 46 year old Jane Jammer comes into Dr Doolittles office with the complaint of an itcy sensation in her gut, but it is not quite painful. On the question where that sensation is located exactly, Mrs. Jammer points to her upper left abdomen but then draws a circle that covers about everything.
So Dr. Doolittle tries to code this chief complaint using a Multiaxial Code for Primary Care Medicine (PRIMAX). PRIMAX might have an axis for sensation (S) and location (L). The doctor is lucky to find 123 "ABDOMEN" as a fairly general descriptor for the location. But the doctor finds only "pain," "numbness," "tension," "heat," and "cold" as sensations. So where does the "itchy but not quite painful" sensation goes into? Unfortunately this code does not come with the category not otherwise classified (NOC) not otherwise specified (NOS) or just other that many classification systems (like ICD) have. So, the physician can not code that chief complaint of his patient.
The physician writes down the following:
Now there are a couple of issues.
First, we said that the print-name would have no meaning whatsoever. We said that in order to prevent (or at least penalize) that kind of losely coding, where people would just be too lazy to do the coding although they could. In this case, the coder tried everything but he couldn't find the sensation in PRIMAX. So he uses the special value ``#other'' that tells us that the printname now does have some meaning. At least it should not be dropped.
Alternatively we could have another optional component of Code Value, named, say, "replacement" of type Character String. so that part would have shown up as follows:
Second, we did not yet introduce special values such as
#null or #other used in the examples here.
This will be an upcoming task.
Third, the PRIMAX is a multiaxial code, it has sensation (S), location (L), and may be more, like timing (T), and the kind of work you were just about to do when the problem appeared (W). PRIMAX (like SNOMED) does not require you to pick a value from every axis. So, noone knows what this #other in PRIMAX refers to, sensation? timing? work-relatedness?
Forth, it seems to be redundant to have a phrase like
Fifth, it also seems like a code phrase does only make sense in certain code systems. For example, in LOINC a code phrase is pretty useless if not contradictory to the (original) style of LOINC (that has been losened up lately). In LOINC you would say
BLD) and then adds to it the modifier that the specimen
was really arterial blood.
Sixth, if the ability to form code phrases depends on the code system, the code system might define a syntax for literal expressions of those phrases, such as "M12345 F03847 D94578" which SNOMED apparently suggests.
On the other hand, some coding systems that do have modifiers (like HCFA procedure codes) do not necessarily specify a syntax to build code phrase literals.
Seventh, even codes that are not originally ment to be used in phrases (like ICD9 used to be long time ago) did evolve to allowing this. Today we see that certain ICD9 codes beg for a second code to specify the meaning more exactly.
We currentle see such a drift towards multiaxiality within LOINC (which makes me worry). Where good ol' LOINC distinguished between a glucose lab test and a glucose test-strip, and while it say this
FICK". Thus: ...
Eighth: sometimes we need to label specific parts in a code phrase. A code phrase is just a container of a flat sequence of code values. Language has deep structure (look at Chomsky's famous noun phrase (NP) and verbal phrase (VP))
Nineth: our data type is already quite complex. If we do a recursion of the EBNF form:
Those are already enough issues to think about. Talk to you on November 5th, 11 EST, same time, same place.
regards
-Gunther Schadow